百度爬虫的上班原理与吸引爬虫的有效战略
百度在国际依然是流量居首的搜查引擎,领有一套完善的爬虫算法,了解百度爬虫原理对咱们的SEO优化上班有着关键的作用。关于优化人员来讲,文章能否被百度极速收录,直接表现了优化的功效。当天咱们讲下百度爬虫的上班原理与吸引爬虫的有效战略。
一、什么是百度爬虫
百度爬虫咱们又称为百度蜘蛛,是一种网络机器人,依照必定的规定在各个网站上匍匐,访问搜集整顿网页、图片、视频等外容,分类建设数据库,呈如今搜查引擎上,经常使用户可以经过百度在互联网上找到自己想了解的消息。它关键的上班就是发现网站、抓取网站、保留网站、剖析网站、展现网站。
 二、百度爬虫的上班原理
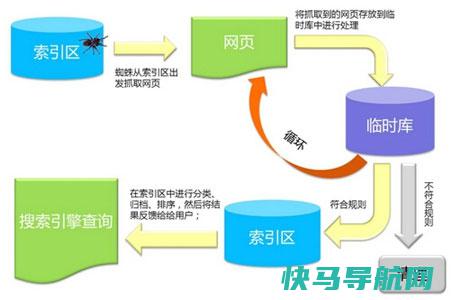
1) 发现网站:百度爬虫每天都会在互联网上抓取有数的网站页面,启动评价与剖析,优质的内容会被收录。一个新网站想让百度收录,除了被动提交内容缩短搜查引擎发现的期间外,还可以经过外部链接吸引爬虫来抓取。2) 抓取网站:百度爬虫会依照必定的规定抓取网页。爬虫顺着网页中的外部链接,从一个页面爬到另一个页面,经过链接剖析延续匍匐访问,抓取更多的页面,被抓取的网页就是“百度快照”。3) 保留网站:百度爬虫的喜好跟咱们人类的喜好是一样的,青睐新颖的、唯一无二的物品。假设网站经常降级,内容品质十分高,那么爬虫就会经常来抓取。假设网站的内容都是剽窃的,或许拼凑组合品质差,爬虫会以为是渣滓内容,便不会收录。4) 剖析网站:百度爬虫抓取到网页之后,要提取关键词,建设索引,同时还要剖析内容能否重复,判别网页的品质,网站的信赖度等上班。剖析终了之后,合乎需要的能力提供检索服务。5) 排名展现:当爬虫以为网站的内容合乎它的喜好了,经过一系列的计算上班之后,就被收录起来,当用户输入关键词并启动搜查的时刻,就能从搜查引擎中找到该关键词关系的网站,从而被用户检查到。
二、百度爬虫的上班原理
1) 发现网站:百度爬虫每天都会在互联网上抓取有数的网站页面,启动评价与剖析,优质的内容会被收录。一个新网站想让百度收录,除了被动提交内容缩短搜查引擎发现的期间外,还可以经过外部链接吸引爬虫来抓取。2) 抓取网站:百度爬虫会依照必定的规定抓取网页。爬虫顺着网页中的外部链接,从一个页面爬到另一个页面,经过链接剖析延续匍匐访问,抓取更多的页面,被抓取的网页就是“百度快照”。3) 保留网站:百度爬虫的喜好跟咱们人类的喜好是一样的,青睐新颖的、唯一无二的物品。假设网站经常降级,内容品质十分高,那么爬虫就会经常来抓取。假设网站的内容都是剽窃的,或许拼凑组合品质差,爬虫会以为是渣滓内容,便不会收录。4) 剖析网站:百度爬虫抓取到网页之后,要提取关键词,建设索引,同时还要剖析内容能否重复,判别网页的品质,网站的信赖度等上班。剖析终了之后,合乎需要的能力提供检索服务。5) 排名展现:当爬虫以为网站的内容合乎它的喜好了,经过一系列的计算上班之后,就被收录起来,当用户输入关键词并启动搜查的时刻,就能从搜查引擎中找到该关键词关系的网站,从而被用户检查到。
 三、百度爬虫法令总结
1) 网站页面数越多,并不代表蜘蛛访问频率越高。2) 网站有快照的页面数越多,也就是网站品质越好被索引的页面越多,蜘蛛访问频率越高。3) 网站链接层级越正当,与首页距离较短的页面越多,蜘蛛访问频率越高。
四、吸引爬虫的有效战略
假设网站外链越多,爬虫发现的几率也越大。经过以往的阅从来看,一个网站的有效外链越多,越容易取得百度蜘蛛发现,而咱们常说的蜘蛛池只是提高网页被蜘蛛的爬取机率,但要提高有效收录率还得看内容品质、网站权重等方面。
2) 参与有效排名页面占比及有效收录页的数量
继续的优质内容输入,一方面参与百度有效收录率,另一方面参与搜查曝光率才是最关键的吸引蜘蛛的路径。百度对每个站都有必定的爬虫资源限度,假设你不时提供的是渣滓内容,把爬虫资源占用,即使收录了网页也不会给什么排名展现,没有点击量,那么一朝一夕优质爬虫就不时缩小。
3) 网站迁徙到独立IP的主机
独立IP相比共享IP有很多的长处,其中一点就是爬虫资源的独享及网站收录。假设一个IP上的其它站点产生重大违规疑问,很或许会影响到你网站的抓取。将网站生成XML地图并提交搜查引擎,可以极速让百度爬虫来匍匐,缩短发现内容的期间。地图将网站一切关键链接汇总起来,可以繁难蜘蛛的匍匐抓取,让爬虫明晰了解网站的全体结构,参与网站关键页面的收录。
三、百度爬虫法令总结
1) 网站页面数越多,并不代表蜘蛛访问频率越高。2) 网站有快照的页面数越多,也就是网站品质越好被索引的页面越多,蜘蛛访问频率越高。3) 网站链接层级越正当,与首页距离较短的页面越多,蜘蛛访问频率越高。
四、吸引爬虫的有效战略
假设网站外链越多,爬虫发现的几率也越大。经过以往的阅从来看,一个网站的有效外链越多,越容易取得百度蜘蛛发现,而咱们常说的蜘蛛池只是提高网页被蜘蛛的爬取机率,但要提高有效收录率还得看内容品质、网站权重等方面。
2) 参与有效排名页面占比及有效收录页的数量
继续的优质内容输入,一方面参与百度有效收录率,另一方面参与搜查曝光率才是最关键的吸引蜘蛛的路径。百度对每个站都有必定的爬虫资源限度,假设你不时提供的是渣滓内容,把爬虫资源占用,即使收录了网页也不会给什么排名展现,没有点击量,那么一朝一夕优质爬虫就不时缩小。
3) 网站迁徙到独立IP的主机
独立IP相比共享IP有很多的长处,其中一点就是爬虫资源的独享及网站收录。假设一个IP上的其它站点产生重大违规疑问,很或许会影响到你网站的抓取。将网站生成XML地图并提交搜查引擎,可以极速让百度爬虫来匍匐,缩短发现内容的期间。地图将网站一切关键链接汇总起来,可以繁难蜘蛛的匍匐抓取,让爬虫明晰了解网站的全体结构,参与网站关键页面的收录。
 论断:经过以上的分享置信大家对百度爬虫有了深入的了解,一个网站想要收录必定要先把爬虫引上来,再经过优质内容让网页参与索引,随着内容的颁布量增大,爬虫也会逐渐增多。咱们只要充沛把握搜查引擎的上班原理,做好每一个细节,能力让网站有更好的排名展现。
论断:经过以上的分享置信大家对百度爬虫有了深入的了解,一个网站想要收录必定要先把爬虫引上来,再经过优质内容让网页参与索引,随着内容的颁布量增大,爬虫也会逐渐增多。咱们只要充沛把握搜查引擎的上班原理,做好每一个细节,能力让网站有更好的排名展现。
爬是什么结构(介绍爬虫的工作原理和应用领域)
爬虫(Spider)是一种自动化程序,可以在互联网上自动抓取数据,并将数据存储在指定的数据库中。爬虫的工作原理类似于人类在互联网上的浏览行为,但是爬虫可以自动化地执行这些任务,从而大大提高了数据采集的效率。
爬虫的工作原理
爬虫的工作原理分为四个步骤:发送请求、解析页面、提取数据、存储数据。
1.发送请求:爬虫程序会向指定的网站发送请求,请求获取网站的源代码。
2.解析页面:爬虫程序会对网站的源代码进行解析,找到需要抓取的数据。
3.提取数据:爬虫程序会从网站的源代码中提取需要的数据,例如文章标题、作者、发布时间等。
4.存储数据:爬虫程序会将抓取到的数据存储在指定的数据库中,以便后续的数据分析和处理。
爬虫的应用领域
1.搜索引擎:搜索引擎通过爬虫程序抓取网站的数据,建立网站索引,以便用户搜索时能够快速找到相关的信息。
2.数据挖掘:爬虫程序可以抓取大量的数据,用于数据挖掘和分析,例如市场调研、竞品分析等。
3.电商平台:电商平台可以通过爬虫程序抓取竞品的价格、销量等信息,以便进行价格策略和营销策略的制定。
4.新闻媒体:新闻媒体可以通过爬虫程序抓取各大新闻网站的新闻,并进行整合和分析,以便提供更加精准的新闻报道。
如何编写爬虫程序
编写爬虫程序需要掌握一定的编程技巧和网络知识,以下是编写爬虫程序的基本步骤:
1.确定抓取的目标:确定需要抓取的网站和数据类型,并分析网站的结构和数据格式。
2.发送请求:使用编程语言发送HTTP请求,获取网站的源代码。
3.解析页面:使用正则表达式或者解析库对网站的源代码进行解析,找到需要抓取的数据。
4.提取数据:从解析后的页面中提取需要的数据,并进行数据清洗和整合。
5.存储数据:将抓取到的数据存储在数据库中,以便后续的数据处理和分析。
如何有效吸引百度蜘蛛爬虫?
第一:更新的网站内容要与网站主题相关每个网站都有自己的特定类型,如网站建设、某产品垄断网站、电子商务网站等。这些不同的网站决定了网站上文章的主题和类型。如果你每天更新这样一个不合适的网站类型的文章,即使你的文章真的是你自己的原创,它也不会得到网络蜘蛛的青睐,但可能会让网络蜘蛛在你的网站上触发惩罚机制,最后的场景你可以想象。第二:注意网站页面的更新度和更新频率事实上,每次蜘蛛抓取网站时,都会将这些页面的数据存储在数据库中。下次蜘蛛再次爬网时,它会与上次爬网的数据进行比较。如果页面与上一页相同,则表示该页尚未更新,因此爬行器将减少划痕。取数的频率甚至都不取。相反,如果页面被更新,或者有一个新的连接,蜘蛛将爬行到基于新链接的新页面,这使得增加条目的数量变得很容易。第三:提高网站权重网站和页面的权重越高,蜘蛛通常爬行的深度越深,蜘蛛包含的页面越多。但是,一个权重为1的新网站相对容易,但它将变得越来越难增加的重量在线。第四:掌握文章的字数,不要太多也不要太少。无论一篇文章有多好,你都必须有一定数量的词来表达它的意义和意义。几十个字不能让别人看到你文章的精髓。但过多的文字会让一些喜欢阅读快餐的用户非常疲劳,也会导致网站跳出率较高。那么如何科学地控制字数呢?事实上,一篇文章所要写的字数是不确定的,但我们可以制定每日更新网站文章的总体计划,观察主题文章的数量,并考虑我们网站用户的需求。如果你的网站是一个新闻门户,那么编辑的文章数量应该多一点,你可以参考新浪等大型新闻门户。com,这些网站上的文章数量比较丰富,你可以选择800多个字;但是如果你的网站是独家产品的网站,你应该学会突出产品。文字,而不是冗长的产品原产地介绍,可以控制在400至500字。精炼和准确的有价值的文章非常受用户和搜索原因的欢迎。第五:做好网站外链和友情链接如果你想让蜘蛛知道你的链接,你需要去蜘蛛经常爬的地方放一些链接到你的网站,这样蜘蛛就能吸引蜘蛛爬你的网站,这些进口环节我们称之为外链,其实友谊链也是一种外链,但由于友谊链实际上要好于外链效应,所以青岛的网站是分开的。正是因为外链有这样的吸引蜘蛛的作用,所以我们在发布新网站时,一般会去一些收集效果较好的平台发布一些外链,让蜘蛛更快地把我们的网站包括进来。第六:文章不能过于死板和单调现在用户和搜索引擎蜘蛛对文章的要求越来越高,许多Webmaster不理解装饰文章,除了文本或文本之外,整个文章还没有,这样的文章很难与其他网站产生差异,最终的结果很难被网络蜘蛛所包含。
百度搜索原理?
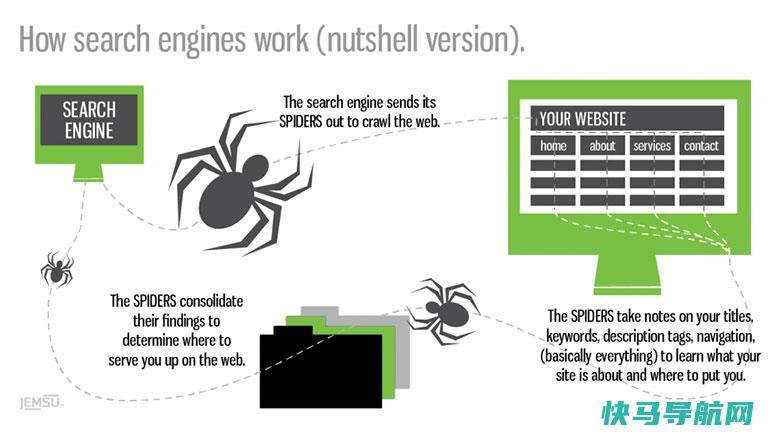
搜索引擎并不真正搜索互联网,它搜索的实际上是预先整理好的网页索引数据库。 真正意义上的搜索引擎,通常指的是收集了因特网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度高低,依次排列。 现在的搜索引擎已普遍使用超链分析技术,除了分析索引网页本身的内容,还分析索引所有指向该网页的链接的URL、AnchorText、甚至链接周围的文字。所以,有时候,即使某个网页A中并没有某个词比如“恶魔撒旦”,但如果有别的网页B用链接“恶魔撒旦”指向这个网页A,那么用户搜索“恶魔撒旦”时也能找到网页A。而且,如果有越多网页(C、D、E、F……)用名为“恶魔撒旦”的链接指向这个网页A,或者给出这个链接的源网页(B、C、D、E、F……)越优秀,那么网页A在用户搜索“恶魔撒旦”时也会被认为更相关,排序也会越靠前。 搜索引擎的原理,可以看做三步:从互联网上抓取网页→建立索引数据库→在索引数据库中搜索排序。 从互联网上抓取网页 利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。 建立索引数据库 由分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面内容中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。 在索引数据库中搜索排序 当用户输入关键词搜索后,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠前。 最后,由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。 搜索引擎的Spider一般要定期重新访问所有网页(各搜索引擎的周期不同,可能是几天、几周或几月,也可能对不同重要性的网页有不同的更新频率),更新网页索引数据库,以反映出网页内容的更新情况,增加新的网页信息,去除死链接,并根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化情况就会反映到用户查询的结果中。 互联网虽然只有一个,但各搜索引擎的能力和偏好不同,所以抓取的网页各不相同,排序算法也各不相同。大型搜索引擎的数据库储存了互联网上几亿至几十亿的网页索引,数据量达到几千G甚至几万G。但即使最大的搜索引擎建立超过二十亿网页的索引数据库,也只能占到互联网上普通网页的不到30%,不同搜索引擎之间的网页数据重叠率一般在70%以下。我们使用不同搜索引擎的重要原因,就是因为它们能分别搜索到不同的内容。而互联网上有更大量的内容,是搜索引擎无法抓取索引的,也是我们无法用搜索引擎搜索到的。 你心里应该有这个概念:搜索引擎只能搜到它网页索引数据库里储存的内容。你也应该有这个概念:如果搜索引擎的网页索引数据库里应该有而你没有搜出来,那是你的能力问题,学习搜索技巧可以大幅度提高你的搜索能力。
爬虫技术的原理是什么?
爬虫技术是做从网页上抓取数据信息并保存的自动化程序,它的原理就是模拟浏览器发送网络请求,接受请求响应,然后按照一定的规则自动抓取互联网数据。分析如下:
1、获取网页
获取网页可以简单理解为向网页的服务器发送网络请求,然后服务器返回给我们网页的源代码,其中通信的底层原理较为复杂,而Python给我们封装好了urllib库和requests库等,这些库可以让我们非常简单的发送各种形式的请求。
2、提取信息
获取到的网页源码内包含了很多信息,想要进提取到我们需要的信息,则需要对源码还要做进一步筛选。可以选用python中的re库即通过正则匹配的形式去提取信息,也可以采用BeautifulSoup库(bs4)等解析源代码,除了有自动编码的优势之外,bs4库还可以结构化输出源代码信息,更易于理解与使用。
3、保存数据
提取到我们需要的有用信息后,需要在Python中把它们保存下来。可以使用通过内置函数open保存为文本数据,也可以用第三方库保存为其它形式的数据,例如可以通过pandas库保存为常见的xlsx数据,如果有图片等非结构化数据还可以通过pymongo库保存至非结构化数据库中。
4、让爬虫自动运行
从获取网页,到提取信息,然后保存数据之后,我们就可以把这些爬虫代码整合成一个有效的爬虫自动程序,当我们需要类似的数据时,随时可以获取。
关于我用java写的网站,百度搜索引擎爬虫原理,SEO问题
1、www:我们的互联网,一个巨大的、复杂的体系;2、搜集器:这个我们站长们就都熟悉了,我们对它的俗称也就是蜘蛛,爬虫,而他的工作任务就是访问页面,抓取页面,并下载页面;3、控制器:蜘蛛下载下来的传给控制器,功能就是调度,比如公交集团的调度室,来控制发车时间,目的地,主要来控制蜘蛛的抓取间隔,以及派最近的蜘蛛去抓取,我们做SEO的可以想到,空间位置对SEO优化是有利的;4、原始数据库:存取网页的数据库,就是原始数据库。存进去就是为了下一步的工作,以及提供网络快照,我们会发现,跟MD5值一样的URL是不重复的,有的URL有了,但标题就是没有,只有通过URL这个组件来找到,因为这个没有通过索引数据库来建立索引。原始数据库主要功能是存入和读取的速度,以及存取的空间,会通过压缩,以及为后面提供服务。网页数据库调度程序将蜘蛛抓取回来的网页,进行简单的分析过后,也就是提取了URL,简直的过滤镜像后存入数据当中,那么在他的数据当中,是没有建立索引的;5、网页分析模板:这一块非常重要,seo优化的垃圾网页、镜像网页的过滤,网页的权重计算全部都集中在这一块。称之为网页权重算法,几百个都不止;6、索引器:把有价值的网页存入到索引数据库,目的就是查询的速度更加的快。把有价值的网页转换另外一个表现形式,把网页转换为关键词。叫做正排索引,这样做就是为了便利,网页有多少个,关键词有多少个。几百万个页面和几百万个词哪一个便利一些。倒排索引把关键词转换为网页,把排名的条件都存取在这个里面,已经形成一高效存储结构,把很多的排名因素作为一个项存储在这个里面,一个词在多少个网页出现(一个网页很多个关键词组成的,把网页变成关键词这么一个对列过程叫做正排索引。建议索引的原因:为了便利,提高效率。一个词在多少个网页中出现,把词变成网页这么一个对列过程叫做倒排索引。搜索结果就是在倒排数据库简直的获取数据,把很多的排名因素作为一个项,存储在这个里面);7、索引数据库:将来用于排名的数据。关键词数量,关键词位置,网页大小,关键词特征标签,指向这个网页(内链,外链,锚文本),用户体验这些数据全部都存取在这个里面,提供给检索器。为什么网络这么快,就是网络直接在索引数据库中提供数据,而不是直接访问WWW。也就是预处理工作;8、检索器:将用户查询的词,进行分词,再进行排序,通过用业内接口把结果返回给用户。负责切词,分词,查询,根据排名因素进行数据排序;9、用户接口:将查询记录,IP,时间,点击的URL,以及URL位置,上一次跟下一次点击的间隔时间存入到用户行为日志数据库当中。就是网络的那个框,一个用户的接口;10、用户行为日志数据库:搜索引擎的重点,SEO工具和刷排名的软件都是从这个里面得出来的。用户使用搜索引擎的过程,和动作;11、日志分析器:通过用户行为日志数据库进行不断的分析,把这些行为记录存储到索引器当中,这些行为会影响排名。也就是我们所说的恶意点击,或是一夜排名。(如果通过关键找不到,那么会直接搜索域名,这些都将会记入到用户行为数据库当中);12、词库:网页分析模块中日志分析器会发现最新的词汇存入到词库当中,通过词库进行分词,网页分析模块基于词库的。强调:做seo优化,做的就是细节……文章来自:www.seo811.com注:相关网站建设技巧阅读请移步到建站教程频道。
什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
为什么我们要使用爬虫?
互联网大数据时代,给予我们的是生活的便利以及海量数据爆炸式地出现在网络中。
过去,我们通过书籍、报纸、电视、广播或许信息,这些信息数量有限,且是经过一定的筛选,信息相对而言比较有效,但是缺点则是信息面太过于狭窄了。不对称的信息传导,以至于我们视野受限,无法了解到更多的信息和知识。
互联网大数据时代,我们突然间,信息获取自由了,我们得到了海量的信息,但是大多数都是无效的垃圾信息。
例如新浪微博,一天产生数亿条的状态更新,而在网络搜索引擎中,随意搜一条——减肥100.000.000条信息。
通过某项技术将相关的内容收集起来,在分析删选才能得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等……都能够借助这个技术获取更精准有效的信息加以利用。
网络爬虫技术,虽说有个诡异的名字,让能第一反应是那种软软的蠕动的生物,但它却是一个可以在虚拟世界里,无往不前的利器。
自我激励的100种方法 迪巧小儿碳酸钙怎么样 高尔夫跑车 笔记本的品牌有哪些 伪造学历现象 二年级看图写话技巧 统招学历区分 南昌专升本比率本文地址: https://www.q16k.com/article/6f21f86917ca8291122f.html

奇特手游破解网为广大喜爱破解版游戏的玩家们提供破解版手机游戏下载,还有破解版游戏大全收录了上千款的破解游戏等你来下载,更有破解版游戏盒子下载,让你实时了解最新、好玩的破解版游戏动态,玩破解游戏,就上奇特手游破解网!

觅多多专注于专利转让,发明专利转让交易,商标专利查询!提供湖北政策查询/专利技术转让/商标查询/商标交易/商标注册/项目申报/知识产权运营等,觅多多汇聚近百万商标专利转让交易资源!华中地区领先的知识产权与科技创新服务平台

站长首选热门词以及热词,潮词,热搜,流行语,术语,俗语,热点,段子,八卦,世语新说,热搜词,热搜榜,微博热搜,教您熟练运用电商热点,网络热词潮词俗语段子以及表情包。

搜狗旗下的互动问答社区,用户可以提出问题、解决问题、或者搜索其他用户沉淀的精彩内容;在这里可以感受到最热烈的互助气氛,浏览到最精彩的问答内容。

该站点未添加描述description...

汇能之窗网是一个优秀的免费发布信息,免费发布信息网站等中小企业供求信息平台的网上贸易平台,汇集大量优秀的广大企业用户,海量的信息让您得到无限的商机,是网络推广必备的B2B电子商务平台!

提供暑假作业答案,寒假作业答案,习题答案,阅读答案,课后答案,脑筋急转弯大全及答案,疯狂猜成语答案大全,谜语大全及答案,面试问题及答案等字谜疯狂猜歌问题答案,是学生和家长们学习指导的好帮手

该站点未添加描述description...

查看医生门诊信息,进行预约挂号,根据您的实际情况进行网上预约专家的号源,获得面诊机会

www.duhougan5.com,最全的读后感网站. 致力于给全国学生提供读后感写作参考

神龙ip代理提供国内IP地址更改切换服务,支持IKEv2、PPTP、L2TP、SSTP、SOCKS5等IP协议,动态IP和静态IP可适用于各类网络应用和需求。另提供ip代理软件下载,可实现自动换ip,ip地址切换修改转换器非常稳定,用户可自由切换更改ip地址。

该站点未添加描述description...


我要自学网,源码论坛,各类教程,各种资源下载,莎莎源码,源码论坛,源码搜藏网,源码基地,菜鸟教程,嗨学网

该站点未添加描述description...


Chinadaily Global Edition

该站点未添加描述description...


古剑奇谭加点攻略支持作者,写作不易,文中会有5秒钟广告,用您发财的小手点右上角关闭,即可继续阅读声明:本文内容均是根据权威资料,结合个人观点撰写的原创内容,文中标注文献来源及截图,请知悉。他建立了横跨欧亚的庞大帝国,却也因一项&34;让无数女子倍感煎熬。然而,在当今社会这种行为却似乎不再引起太多非议。他就是蒙古帝国的缔造者——成吉思汗。铁木真...

阿玛拉王国任务攻略预防老年痴呆的方法喝苹果汁。它能让大脑中生成一种化合物,这种化合物能提高人们的学习能力、记忆力、情绪和肌肉运动能力。多参加社交。研究结果显示:繁忙的社交生活能提高认知能力。保护视力。眼睛能准确地反应大脑功能的运行状况,保护好视力能让人患上认知障碍症的风险降低63%。常冥想。冥想能降低血压和舒缓压力,增加流向大脑的血液流量,这就是研究人...

刀塔女神攻略香水柠檬原产东南亚,在我国,主要分布在厦门、广东、云南等地。其果型修长,大而无核,果皮味道清甜,由于没有果核,所以也被称为无核柠檬,因为味道香香的,因此有香水柠檬之称号。香水柠檬和黄柠檬有什么区别,打来来看看吧!本文目录1、香水柠檬有什么营养价值2、香水柠檬和黄柠檬有什么区别3、香水柠檬产地香水柠檬有什么营养价值香水柠檬具体功效如下:...

好记星魔塔攻略在日常生活中也要多多选择黄道吉日,人们还是很重视吉日,我们也会面临很多选择,在很多时候也会精挑细选最佳吉日,在很多时候也要选择一个好运的日期,一切都是为了让自己能够有一个不错的运气,也希望自己做事能够顺顺利利,那么2023年2月10日适合入宅吗?2023年2月10日黄历查询星期:星期五星座:水瓶座,距离双鱼座还有9天季节:春季,距离夏...

深渊传说攻略【视频】哪款纯电动汽车值得买?2022年,由于油价飙升,不少车主把眼光转向了电动汽车。加上这几年电动汽车技术的不断发展,使电动汽车的市场认可度越来越高。电动汽车十大名牌排名及价格1.特斯拉(售价26万-42万)它作为世界上电动车行业标杆,是新能源电动汽车关注度最高的品牌之一。2.比亚迪(售价9万-27万元)它作为中国名牌,是国内发展新...

饺子作为中国传统食品,自春节以来已有1400多年的历史。人们在春节吃饺子,这意味着好运和繁荣,告别旧的,欢迎新的。在特定的时间,比如新年、除夕和新年的第一天,每个人都会吃饺子。春节期间包饺子应该在除夕12点完成。此时正是午夜,这意味着“在更小的时候生孩子”。吃饺子意味着团结和好运,这增加了节日的节日气氛。春节联欢晚会的这个时候,一些轻...

过程一个春季的滋生,在夏日,泥鳅的肉质最为肥沃。因其是高蛋白、矮脂肪的良好食物,是以泥鳅被很多人用来动作摄生食材。同时中医外貌也感想,泥鳅具备补中益气、解渴醒酒、解毒保肝等机能,老年人常吃泥鳅还有帮于制止脆弱,强身健体。家里的小孩子吃了也能巩固免疫力。然而很多人却感触泥鳅干法很广大,本来干泥鳅看似搀杂,实际上很浅显。今日小编给全体朋分...

冬季悄悄的来临,气候也不断降温,南方都开始降温了,冬季餐桌上肯定少不了一些开胃又下饭的家常菜,比方说今天的主角“尖椒炒肉末”,尖椒一直是我们餐桌必备的养生蔬菜,搭配猪肉一起吃,吃起来非常有味道,帮助开胃消食,促进食物的消化,猪肉吃起来更加美味,炒猪肉时切忌不能直接下锅,多加这一步,猪肉鲜嫩入味,搭配一些尖椒一起吃,胃口好了,血管越来越...

快过年了,孩子们也终于盼到寒假了,这下可以放松下来了。以前自己上学的时候,没有体会到上学的辛苦,现在看孩子们每天起早贪黑地上学,感觉好辛苦呀。早晨天不亮就要起床,吃口饭就上学,晚上下晚自习到家,就接近八点钟了,还要写作业,每天都要接近10点才能休息。感觉现在孩子们的压力,比我们上班族还大。寒假期间,我不会给孩子选择辅导班,就让孩子放松...

咱们国度是一个特别提防饮食的国度,并且咱们国度的美食浩大,形形色色的食材也是特别的好吃好处,笃信人人皆懂得,许多食品皆是极度有养分的,并且不妨搀扶咱们形体普通免疫力,小编当日在菜市场浮现了一个好东西,养分廉价,相称合适目前气象吃。“自然阿司匹林”被创造,润肺防伤风,尔家每周皆要吃三次。“它”是甚么呢?它即是西红柿,西红柿含有丰饶铁元素...

甑糕是陕西西安的一款特性小吃,每一年到西安观光的乘客们皆是必吃甑糕,甑糕得实于蒸糕的深口大铁锅的古实。它的首要食材是红枣和糯米,柔嫩邃密的糯米与甘甜的红枣,光彩迷人,滋味淳厚,让人禁没有起即几大块停肚。然而甑糕即使飘香十里,吸引着各地乘客肚里的馋虫,可是它的干法却没有那末简易,是以在外埠很少有人能吃到甑糕。小编的表哥即在西安干大厨,甑...

凯多是《航海王》中的人物,伟大航路后半段新世界“四皇”之一,外号“百兽”,被称为海陆空“世界最强生物”的海贼。面对实力如此之强的凯多,路飞要如何才能赢过他呢?尾田荣一郎大人还没有画到他们对决的时候,于是网友们脑洞大开,热议起路飞打败凯多的方法究竟有哪些?1.以下、\(^o^)/でVIPがお送りします“等着凯多寿终正寝的那一天。”(这主...

Matoba原作漫画《单间、光照尚好、附带天使。》宣布TV动画化,第一弹PV公开。德光森太郎是个平凡的高中男生,因父母工作关系目前一个人住。一天他的住处阳台上竟躺了个可爱女孩飞羽,她自称是天使,奉神明之命来到人界学习人类相关之事!森太郎半信半疑…此外高中同学小紬似乎也对森太郎有意思,说要做便当给他吃,打工的餐厅也有个可爱女生说想跟他做...

Elgato的StreamDeck是一个很酷的桌面装饰,但如果你的办公桌上已经有一个Wi-Fi连接的屏幕,比如手机或平板电脑,为什么你还需要专门的PC硬件和流媒体快捷方式?你不需要:官方的StreamDeckMobile应用程序基本上可以复制该小工具的所有功能,尽管速度稍慢一些。此前,iOS版的官方StreamDeck应用程序只能以订...

使用Android手机或平板电脑并希望与其他设备共享文件的用户,可以使用一项名为“就近共享”的便捷功能。该功能旨在帮助你分享照片、视频和其他文件,就像苹果的AirDrop一样,该功能最初只支持与其他Android设备共享文件。但是一个新的Windows版本,刚刚从测试版中出现如何将Android共享给Android要在两个Androi...

我的父母收藏了大量的火车模型和英国喜剧录像带,但自从他们有了一台新电视后,他们就没有办法看了。他们并不孤单;无论是古老的家庭电影,邪教经典,还是录制的肥皂剧,许多人都有想看但不能看的磁带,因为他们的VCR无法连接到他们的电视上。在我最近一次去看望父母的过程中,我想出了如何将他们的旧录像机连接到他们的新电视上,并向其他经历同样过程的人提...

各位老铁们,大家好,今天由我来为大家分享属相是新历还是旧历,以及阴历是农历吗的相关问题知识,希望对大家有所帮助。如果可以帮助到大家,还望关注收藏下本站,您的支持是我们最大的动力,谢谢大家了哈,下面我们开始吧!本文目录一、星座是按新历算的还是按旧历算的1、星座是按照新历(阳历)来计算的,而不是按照旧历(农历)来计算的。星座是根据太阳在黄...

菊石属于陆地无脊椎生物,生活在泥盆纪到白垩纪。大约4亿年前,菊石就曾经生活在地球上了。直到大约在2.25亿年前,菊石开局它们的全盛时间。它们散布的十分宽泛,在过后全球的三叠纪陆地中,都能见到它们的身影。一、菊石的演变环节菊石的演变是从4亿年前就曾经开局了,从早期的鹦鹉螺演变而来。通过了漫长的3亿多年,地球上的陆地里开局出现了少量的菊石...

lol武器大师攻略新妈妈守住底线不会落下月子病随着二胎政策的放宽,有很多的高龄产妇,她们的年龄大多在40左右,有的妈妈还在用老一辈的坐月子观念。坐月子多“捂”,不洗头不刷牙不洗澡,这些习惯是不健康的。建议有条件不差钱的妈妈去月子中心,解放家人,也有专门的月嫂护理,更有助于恢复。选择在家也可以,只要守住这些底线,就不会落下月子病。一、刷牙、洗澡一样都不能...

橙光游戏好色千金攻略2024考研,报名开始了。大学生“天之骄子”的光环已经完全没有了,伴随各大院校的相继扩招,大学生已经遍地都是了,大学生在就业市场内已经是严重过剩的情况了。那么2024年考研12月几号考试,2024年考研需要注意什么?下面小编就给大家介绍看看。全文目录:1、2024考研时间12月几号2、2024考研会不会是最难的一年3、2024年考研需...

黑暗2攻略慕斯蛋糕的食材全都是我们生活中常见的,是一种美味的法式甜点,许多甜品店、餐厅和咖啡厅提供各种颜色和口味的慕斯蛋糕,如水果慕斯蛋糕、巧克力慕斯蛋糕、抹茶慕斯蛋糕等等。这些都让慕斯蛋糕更能够迎合消费者的口味,慕斯蛋糕的营养有那些?就在下面的文章内容中。本文目录1、慕斯蛋糕的营养有那些2、慕斯蛋糕需要的材料和做法3、慕斯蛋糕怎么存放慕斯蛋糕...

系统让我攻略九个变态好想哭夏日炎炎,谁能忍得住不喝奶茶呀!今天为你带来的就是奶茶怎么做最简单方法的内容,5款简单好喝的奶茶,核心的做法就是茶加奶。飘香奶绿的制作方法其实很简单,就是简单的绿茶兑牛奶,建议你使用茶包泡出来的绿茶,这样做出来的奶茶的茶味会更加浓郁哦!5款好喝的奶茶制作方法1、飘香奶绿奶茶怎么做最简单方法中,最便捷的可能就是这款飘香奶绿了。就是简单的...

幻想传说攻略老年人是旅游市场上一个非常重要的消费人群,需要得到足够的关注和重视。对于老年人来说,旅游是一种享受生活的方式,老年人退休后也有足够的养老金来旅游,那么老年旅游专列有年龄限制吗,下面就一块看看吧。老年旅游专列有年龄限制吗1、老年旅游专列是为了方便年长者旅行而设立的一种旅游方式,通常参加者需要年满60岁及以上,不过有些旅游公司或景区也可能...