搜查引擎的上班原理:抓取、索引和排名
搜查引擎是应对机制,它的存在是为了发现、了解和组织互联网内容,以便为用户搜查的疑问提供最关系的结果,那么搜查引擎的上班原理就有必要了解下了。为了出如今搜查结果中,你的内容首先要对搜查引擎可见,其无所谓被收录,假设你的网页没有被索引,那将永远不会出如今 SERP(搜查引擎结果页面)中。
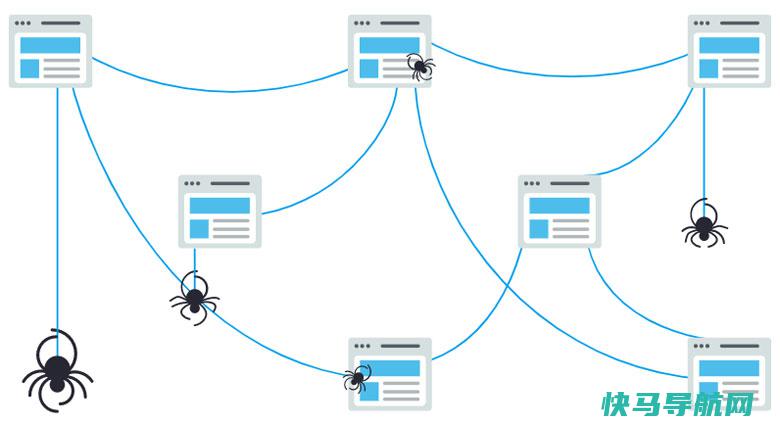 Googlebot首先失掉几个网页,而后依照这些网页上的链接查找新网址。经过沿着这条链接门路腾跃,爬虫能够找到新内容并将其减少到名为Caffeine的索引系统中,这是一个蕴含已发现 URL 的庞大数据库,在用户搜查该 URL 上的内容时做出很好的婚配。搜查引擎处置和存储它们在索引中找到的消息,索引是一个渺小的数据库,蕴含已发现的一切内容,并足够为搜查者提供服务。当有人口头搜查时,搜查引擎会在其索引中搜查高度关系的内容,而后对该内容启动排序,以处置搜查者的查问。这种按关系性对搜查结果启动排序称为排名,普通来说,你可以假定网站排名越高,搜查引擎以为该网站与查问需求越关系。你也可以将网站的局部内容或所有内容阻止搜查引擎来抓取,只管这样做或者是有要素的,但假设你宿愿搜查者找到你的内容,你必定先确保爬虫可以访问它并且可以编入索引。
二、如何检查网站在搜查引擎中的索引
正如刚刚提到的搜查引擎的上班原理,确保你的网站被抓取并编入索引是出如今 SERP 中的先决条件。假设你曾经有一个网站,可以先检查索引中的页面数量。审核索引页面的一种方法是“site:krseo.com”,前往谷歌并在搜查栏中输入以上命令,这将前往 Google 在其索引中针对指定站点的结果:
Googlebot首先失掉几个网页,而后依照这些网页上的链接查找新网址。经过沿着这条链接门路腾跃,爬虫能够找到新内容并将其减少到名为Caffeine的索引系统中,这是一个蕴含已发现 URL 的庞大数据库,在用户搜查该 URL 上的内容时做出很好的婚配。搜查引擎处置和存储它们在索引中找到的消息,索引是一个渺小的数据库,蕴含已发现的一切内容,并足够为搜查者提供服务。当有人口头搜查时,搜查引擎会在其索引中搜查高度关系的内容,而后对该内容启动排序,以处置搜查者的查问。这种按关系性对搜查结果启动排序称为排名,普通来说,你可以假定网站排名越高,搜查引擎以为该网站与查问需求越关系。你也可以将网站的局部内容或所有内容阻止搜查引擎来抓取,只管这样做或者是有要素的,但假设你宿愿搜查者找到你的内容,你必定先确保爬虫可以访问它并且可以编入索引。
二、如何检查网站在搜查引擎中的索引
正如刚刚提到的搜查引擎的上班原理,确保你的网站被抓取并编入索引是出如今 SERP 中的先决条件。假设你曾经有一个网站,可以先检查索引中的页面数量。审核索引页面的一种方法是“site:krseo.com”,前往谷歌并在搜查栏中输入以上命令,这将前往 Google 在其索引中针对指定站点的结果:
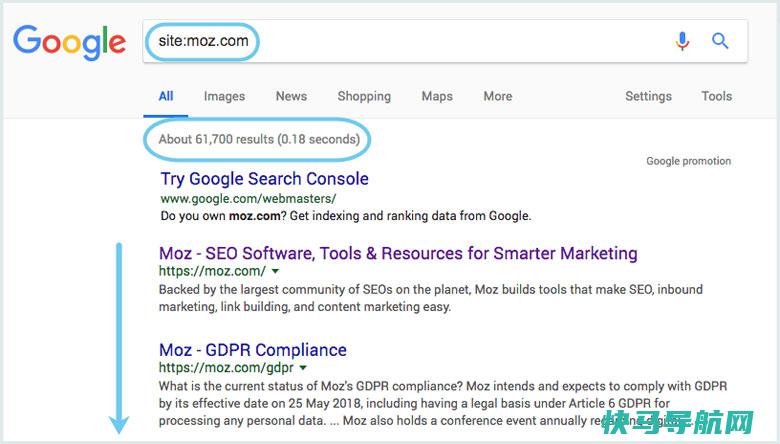 Google 显示的结果数量(请参阅上图的“关于 XX 结果”)并不准确,但它确实可以让你分明的了解网站哪些页面被编入索引,以及它们在搜查结果中的显示方式。要取得更准确的结果,请经常使用 Google Search Console 中的索引笼罩率报告。假设你目前没有,可以注册一个收费的Google Search Console 帐户。经常使用此工具,可以为你的网站提交站点地图,并监控实践减少到 Google 索引中的提交页面数量等。假设的网站没有出如今搜查结果中,或者有以下几个要素:1) 你的网站是全新的,尚未被抓取。2) 你的网站没有在任何外部网站树立链接。3) 你网站的导航使爬虫难以有效的抓取它。4) 你的站点存在阻止爬虫抓取的代码,这些代码会阻止搜查引擎收录网页。5) 你的网站存在重大品质疑问而遭到 Google 的处分。
三、如何让搜查引擎抓取你的网站
假设你经常使用 Google Search Console 或“site:domain.com”发现索引中缺少某些关键页面和某些不关键的页面被失误地编入索引,则可以经过一些优化更好的指点 Googlebot 抓取你的网页内容。比如经过GSC的网址审核将关键页面提交给Google优先参与索引、经过robots.txt通知搜查引擎哪些页面不想让 Googlebot 找到。包括诸如内容稀少的旧 URL、重复 URL(例如电子商务的排序和过滤参数)、不凡促销代码页等外容。Robots.txt 文件位于网站的根目录(例如 yourdomain.com/robots.txt),并在文档中写明让搜查引擎抓取和不抓取的文件门路。假设 Googlebot 找不到某个网站的 robots.txt 文件,它会继续抓取该网站;假设找到这个文件理论会遵照规定并继续抓取该网站。你还可以经过提交XML站点地图让爬虫发现和索引你的网页。确保 Google 找到你网站所有页面的最简双方法之一是创立一个合乎 Google 规范的Sitemap文件并经过 Google Search Console 提交。它可以协助爬虫跟踪到你一切关键页面的门路并将其编入索引。
Google 显示的结果数量(请参阅上图的“关于 XX 结果”)并不准确,但它确实可以让你分明的了解网站哪些页面被编入索引,以及它们在搜查结果中的显示方式。要取得更准确的结果,请经常使用 Google Search Console 中的索引笼罩率报告。假设你目前没有,可以注册一个收费的Google Search Console 帐户。经常使用此工具,可以为你的网站提交站点地图,并监控实践减少到 Google 索引中的提交页面数量等。假设的网站没有出如今搜查结果中,或者有以下几个要素:1) 你的网站是全新的,尚未被抓取。2) 你的网站没有在任何外部网站树立链接。3) 你网站的导航使爬虫难以有效的抓取它。4) 你的站点存在阻止爬虫抓取的代码,这些代码会阻止搜查引擎收录网页。5) 你的网站存在重大品质疑问而遭到 Google 的处分。
三、如何让搜查引擎抓取你的网站
假设你经常使用 Google Search Console 或“site:domain.com”发现索引中缺少某些关键页面和某些不关键的页面被失误地编入索引,则可以经过一些优化更好的指点 Googlebot 抓取你的网页内容。比如经过GSC的网址审核将关键页面提交给Google优先参与索引、经过robots.txt通知搜查引擎哪些页面不想让 Googlebot 找到。包括诸如内容稀少的旧 URL、重复 URL(例如电子商务的排序和过滤参数)、不凡促销代码页等外容。Robots.txt 文件位于网站的根目录(例如 yourdomain.com/robots.txt),并在文档中写明让搜查引擎抓取和不抓取的文件门路。假设 Googlebot 找不到某个网站的 robots.txt 文件,它会继续抓取该网站;假设找到这个文件理论会遵照规定并继续抓取该网站。你还可以经过提交XML站点地图让爬虫发现和索引你的网页。确保 Google 找到你网站所有页面的最简双方法之一是创立一个合乎 Google 规范的Sitemap文件并经过 Google Search Console 提交。它可以协助爬虫跟踪到你一切关键页面的门路并将其编入索引。
 四、与排名关系的一些数据目的
在谷歌排名中,介入度目的指的是示意搜查者如何经过搜查结果与你的网站互动的数据。这包括以下内容:1) 点击次数(来自搜查的访问)2) 页面逗留期间(访问者退出之前在页面上逗留的期间)3) 跳出率(用户仅检查一个页面的百分比)4) Pogo-sticking(点击一个搜查结果,而后极速前往 SERP 以选用另一个结果)依据谷歌前搜查品质主管Udi Manber 的说法:排名自身受点击数据的影响,假设咱们发现,关于特定查问,80% 的人点击 #2,而只要 10% 的人点击 #1,过一段期间咱们就会发现 #2 或者是人们想要的,所以咱们会优化它的排名。
各种测试曾经证明,谷歌将依据搜查者的介入度调整 SERP 顺序:
1) Rand Fishkin 之前的测试让大概 200 人点击来自 SERP 的 URL 后,第 7 名的结果回升到第 1 名。幽默的是,排名优化仿佛与访问链接用户的位置有关。在许多介入者所在的美国地域,排名位置飙升,而在谷歌加拿大、澳大利亚等页面上的排名依然较低。2) Larry Kim 经过测试一些抢手页面及其平均逗留期间的比拟后标明,谷歌算法会降低逗留期间较短页面的排名位置。在网页排名方面,介入度目的就像一个理想审核器,它不会扭转你网页的主观品质。链接和内容等主观要素首先对页面启动排名,而后介入度目的可以协助谷歌在用户体验方面启动排名调整。假设搜查者的行为标明他们更青睐其余页面,则你的排名或者会降低。
四、与排名关系的一些数据目的
在谷歌排名中,介入度目的指的是示意搜查者如何经过搜查结果与你的网站互动的数据。这包括以下内容:1) 点击次数(来自搜查的访问)2) 页面逗留期间(访问者退出之前在页面上逗留的期间)3) 跳出率(用户仅检查一个页面的百分比)4) Pogo-sticking(点击一个搜查结果,而后极速前往 SERP 以选用另一个结果)依据谷歌前搜查品质主管Udi Manber 的说法:排名自身受点击数据的影响,假设咱们发现,关于特定查问,80% 的人点击 #2,而只要 10% 的人点击 #1,过一段期间咱们就会发现 #2 或者是人们想要的,所以咱们会优化它的排名。
各种测试曾经证明,谷歌将依据搜查者的介入度调整 SERP 顺序:
1) Rand Fishkin 之前的测试让大概 200 人点击来自 SERP 的 URL 后,第 7 名的结果回升到第 1 名。幽默的是,排名优化仿佛与访问链接用户的位置有关。在许多介入者所在的美国地域,排名位置飙升,而在谷歌加拿大、澳大利亚等页面上的排名依然较低。2) Larry Kim 经过测试一些抢手页面及其平均逗留期间的比拟后标明,谷歌算法会降低逗留期间较短页面的排名位置。在网页排名方面,介入度目的就像一个理想审核器,它不会扭转你网页的主观品质。链接和内容等主观要素首先对页面启动排名,而后介入度目的可以协助谷歌在用户体验方面启动排名调整。假设搜查者的行为标明他们更青睐其余页面,则你的排名或者会降低。
 论断:如今本地化结果受理想数据的影响,这种交互性是搜查者与本地企业互动和照应的方式,因为 Google 宿愿向搜查者提供最好、最关系的本地业务,因此他们经常使用实时介入度目的来确定品质和关系性是十分无心义的。不过咱们不用了解 Google 算法的前因结果(这依然是个谜!),只要要对搜查引擎的上班原理(如何爬取、索引、存储和排名)有一个基础的了解即可。
论断:如今本地化结果受理想数据的影响,这种交互性是搜查者与本地企业互动和照应的方式,因为 Google 宿愿向搜查者提供最好、最关系的本地业务,因此他们经常使用实时介入度目的来确定品质和关系性是十分无心义的。不过咱们不用了解 Google 算法的前因结果(这依然是个谜!),只要要对搜查引擎的上班原理(如何爬取、索引、存储和排名)有一个基础的了解即可。
搜索引擎原理?
搜索引擎是应用在网络上方便的检索信息而产生的。
所有搜索引擎的祖先是1990年由加拿大蒙特利尔大学的学生Alan发明的,虽然当时万维网还没出现,但是在网络中传输文件已经相当频繁了,由于大量的文件散步在各个分散的FTP主机中,查询起来非常不便于是Alan等想到了开发一个可以用文件名查找文件的系统,于是便有了ARCHIE,这就是最早的搜索引擎雏形。
搜索引擎的工作原理主要就是四个步骤:爬行,抓取,检索,显示。
搜索引擎放出蜘蛛在互联网上爬行,目的是为了发现新的网站和最新的网页内容,从而经过搜索引擎特定程序分析后决定是否抓取这些信息,抓取后然后将其放到索引数据库中,顾客在搜索引擎网站上检索信息时,就会在结果页上出现与检索词相关的信息,并根据与检索词的相关度进行拍序,这就是搜索引擎的工作原理和步骤。
了解搜索引擎工作原理是从事SEO人员需具备的基本知识。
搜索引擎的工作原理是什么?
搜索引擎的工作原理总共有四步:
第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链
接,所以称为爬行。
第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第三步:预处理,搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
第四步:排名,用户在搜索框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。
不同的搜索引擎查出来的结果是根据引擎内部资料所决定的。比如:某一种搜索引擎没有这种资料,您就查询不到结果。
扩展资料:
定义
一个搜索引擎由搜索器、索引器、检索器和用户接四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
起源
所有搜索引擎的祖先,是1990年由Montreal的McGill University三名学生(Alan Emtage、Peter
Deutsch、Bill Wheelan)发明的Archie(Archie FAQ)。Alan Emtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件 。
由于Archie深受欢迎,受其启发,Nevada System Computing Services大学于1993年开发了一个Gopher(Gopher FAQ)搜索工具Veronica(Veronica FAQ)。Jughead是后来另一个Gopher搜索工具。
参考资料来源:网络百科-搜索引擎
搜索引擎的工作原理是怎样的?
搜索引擎的工作原理包括如下三个过程:首先在互联中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
1、抓取网页。
每个独立的搜索引擎都有自己的网页抓取程序(spider)。
Spider顺着网页中的超链接,连续地抓取网页。
被抓取的网页被称之为网页快照。
由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
发现、抓取网页信息需要有高性能的“网络蜘蛛”程序(Spider)去自动地在互联网中搜索信息。
一个典型的网络蜘蛛工作的方式,是查看一个页面,并从中找到相关信息,然后它再从该页面的所有链接中出发,继续寻找相关的信息,以此类推,直至穷尽。
网络蜘蛛要求能够快速、全面。
网络蜘蛛为实现其快速地浏览整个互联网,通常在技术上采用抢先式多线程技术实现在网上聚集信息。
通过抢先式多线程的使用,你能索引一个基于URL链接的Web页面,启动一个新的线程跟随每个新的URL链接,索引一个新的URL起点。
当然在服务器上所开的线程也不能无限膨胀,需要在服务器的正常运转和快速收集网页之间找一个平衡点。
在算法上各个搜索引擎技术公司可能不尽相同,但目的都是快速浏览Web页和后续过程相配合。
目前国内的搜索引擎技术公司中,比如网络公司的网络蜘蛛采用了可定制、高扩展性的调度算法使得搜索器能在极短的时间内收集到最大数量的互联网信息,并把所获得的信息保存下来以备建立索引库和用户检索。
2、处理网页。
搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。
其中,最重要的就是提取关键词,建立索引库和索引。
其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
索引库的建立关系到用户能否最迅速地找到最准确、最广泛的信息,同时索引库的建立也必须迅速,对网络蜘蛛抓来的网页信息极快地建立索引,保证信息的及时性。
对网页采用基于网页内容分析和基于超链分析相结合的方法进行相关度评价,能够客观地对网页进行排序,从而极大限度地保证搜索出的结果与用户的查询串相一致。
新浪搜索引擎对网站数据建立索引的过程中采取了按照关键词在网站标题、网站描述、网站URL等不同位置的出现或网站的质量等级等建立索引库,从而保证搜索出的结果与用户的查询串相一致。
新浪搜索引擎在索引库建立的过程中,对所有数据采用多进程并行的方式,对新的信息采取增量式的方法建立索引库,从而保证能够迅速建立索引,使数据能够得到及时的更新。
3、提供检索服务。
用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
用户检索的过程是对前两个过程的检验,检验该搜索引擎能否给出最准确、最广泛的信息,检验该搜索引擎能否迅速地给出用户最想得到的信息。
对于网站数据的检索,新浪搜索引擎采用多进程的方式在索引库中检索,大大减少了用户的等待时间,并且在用户查询高峰时服务器的负担不会过高(平均的检索时间在0.3秒左右)。
对于网页信息的检索,作为国内众多门户网站的网页检索技术提供商的网络公司其搜索引擎运用了先进的多线程技术,采用高效的搜索算法和稳定的UNIX平台,因此可大大缩短对用户搜索请求的响应时间。
作为慧聪I系列应用软件产品之一的I-Search2000采用的超大规模动态缓存技术,使一级响应的覆盖率达到75%以上,独有的自学习能力可自动将二级响应的覆盖率扩充到20%以上。
选自新华云科论搜索引擎
百度的搜索引擎的流程是什么?哪个高手指教一下.
分类:电脑/网络 >> 互联网 解析: 搜索引擎的工作原理 可以分为三个部分 1、抓取网页 每个独立的搜索引擎都有自己的网页抓取程序(spider)。
Spider顺着网页中的超链接,连续地抓取网页。
由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页 搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。
其中,最重要的就是提取关键词,建立索引文件。
其他还包括去除重复网页、分析超链接、计算网页的重要度。
3、提供检索服务 用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
搜索引擎工作原理
搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(spider)。爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
搜索引擎的工作过程是怎样的?
搜索引擎的工作过程是一个复杂的过程,通常包括以下步骤:1. **抓取(Crawling)**:搜索引擎会使用自动化的程序,称为网络爬虫或蜘蛛,来浏览互联网上的网页。
爬虫从一个网页到另一个网页,通过跟踪超链接和索引文本内容,将网页的内容下载到搜索引擎的数据库中。
2. **索引(Indexing)**:搜索引擎会将抓取的网页内容组织成一个庞大的数据库或索引。
这个索引包含了网页的文本、图像、链接、关键词等信息。
3. **处理查询(Processing Queries)**:当用户在搜索引擎中输入查询时,搜索引擎会处理这个查询并分析用户的意图。
它会考虑查询中包含的关键词、搜索历史、地理位置等因素。
4. **排名(Ranking)**:一旦搜索引擎了解了用户的查询,它会根据一系列算法来确定哪些网页最相关。
这通常涉及到对网页的内容、质量、链接数量等因素进行评估。
5. **显示结果(Displaying Results)**:最终,搜索引擎会根据排名,将最相关的网页结果显示给用户。
搜索结果通常以列表的形式呈现,包括标题、描述和链接,用户可以点击链接查看更多详细信息。
6. **重复过程**:搜索引擎不断地重复这个过程,定期抓取新的网页内容,更新索引,以确保搜索结果的时效性和准确性。
这些步骤只是搜索引擎工作的基本概况,实际上,搜索引擎的内部工作更为复杂,涉及大量的算法和数据处理。
搜索引擎公司通常保密其具体的搜索算法,以保护其商业机密。
不同的搜索引擎可能使用不同的算法和技术来提供搜索结果,这也是为什么搜索结果在不同搜索引擎上可能会有所不同的原因。
本文地址: https://www.q16k.com/article/820a5d16408a43baac31.html

青岛服务之家网为您提供青岛分类信息,青岛生活服务,青岛实体商铺信息,是多元化的青岛便民服务平台:主要定位:青岛生活服务网,青岛分类信息网,青岛实体商铺网,青岛免费发布信息平台,是青岛主流多元化便民信息平台;

招贤纳士网为燃气,化工,医疗,食品,旅游,建筑,服装,电力,石油,环保,外语,传媒,物流,教育,金融,机械等行业提供职位搜索,简历投递,猎头服务,人才评测,培训信息,校园招聘,人事外包,网络招聘,报纸招聘,等专业的服务

该站点未添加描述description...
邦亿房产网提供兴义二手房信息、兴义新房信息、兴义租房信息、兴义房价查询、楼盘销售代理等业务,邦亿房产是黔西南州公认的大型专业房地产综合运营商,目前邦亿房产线下开设多家门店, 为您提供从委托到交易、过户、银行按揭等全流程服务,兴义买房卖房上邦亿房产网,让房产交易不再难。
聚沙玩具儿童玩具小店,我们直营各类积木玩具、彩泥手工、粘土手工、益智玩具、鲁班锁、超轻粘土、乐高积木玩具、积木拼装玩具大全,儿童绘本、成长纪念册等一手玩具小店。
首页,深圳市卓凡动力电子有限公司
本版是新乡的驴友户外爱好者交流平台网站,有新乡的徒步爬山露营户外活动召集、游记分享、线路攻略、驴友俱乐部微信群QQ群等内容,8264户外
这里是浙江白云源电气有限公司在传众网的商铺,该单位主要从事:DY100化油器等!地址位于:浙江杭州市浙江桐庐县桐君街道阆苑路66号

东莞市宇鑫机电有限公司是一家专业生产全球高端鼓风机的厂家,主营:高压风机,漩涡气泵,中压鼓风机,鼓风机厂家,漩涡气泵,透浦式中压风机,环形高压风机,一机吹吸两用,无油气,高压差,免保养!
北京市第二中学
该站点未添加描述description...

山东面粉,山东面粉厂,山东面粉价格,山东面粉厂家-山东冠县腾达面粉厂
初中教师网,是一家专业为初中教师、学生提供教学资源服务的网站,经过不断努力网站拥有大量最新的试题、试卷、课件、导学案、教案等教学资源免费提供给广大用户,力争做最专业的教学资源网站!
库尔勒小生活网免费信息发布平台提供:库尔勒招聘信息,库尔勒人才网,库尔勒房产,库尔勒交友,库尔勒二手,库尔勒宠物,库尔勒二手房,库尔勒教育,库尔勒租房,库尔勒生活服务等相关信息,是小生活网最得力的免费信息发布平台。
微播小说,最热门的免费小说网站,提供武侠仙侠,奇幻玄幻,科幻灵异,都市言情,穿越女频,青春校园,历史军事,网游竞技,职业官场等网络热门的书籍下载跟阅读!
-重庆峰琰文化传媒有限公司经营户外广告屏,重庆LED户外广告屏请联系我们,解放碑步行街户外广告屏商圈广告屏由我公司主要经营。
河北海兴红旗体育器材有限公司是一家中高端体育装备制造商,主要产品有:NSCC国体认证户外健身器材和校园器材、国际篮联FIBA认证篮球架系列、NSCC国体认证多功能笼足器材、可拆装式移动仿真冰(液态合成冰、陆地冰壶、冰壶赛道、旱冰场)、田径器材系列等。
四川雨水收集系统公司推荐雨之润新材料科技主要从事四川雨水回用系统设计和四川PP模块安装以及四川虹吸排水工程施工,我司致力于新型环保节能产品研发设计与生产,可为您提供土工膜等各类四川透水材料销售等业务,业务涵盖范围广泛,详细信息欢迎新老客户来电咨询.

搜查引擎是应对机制,它的存在是为了发现、了解和组织互联网内容,以便为用户搜查的疑问提供最关系的结果,那么搜查引擎的上班原理就有必要了解下了。为了出如今搜查结果中,你的内容首先要对搜查引擎可见,其无所谓被收录,假设你的网页没有被索引,那将永远不会出如今SERP(搜查引擎结果页面)中。一、搜查引擎的上班原理搜查引擎经过三个关键配置上班:1...
每个新版本的iOS和iPadOS都会抛弃某些较旧的iPhone和iPad型号。你的旧设备要么无法运行新操作系统的某些功能,要么根本无法更新。但如果你不确定自己拥有的是什么型号,或者它是否可以运行最新的软件,你能做什么呢?诀窍在于定位型号,然后将其与特定一代设备相匹配。这听起来可能很有挑战性,但一旦你知道到哪里去找,它就不太难了。我的i...
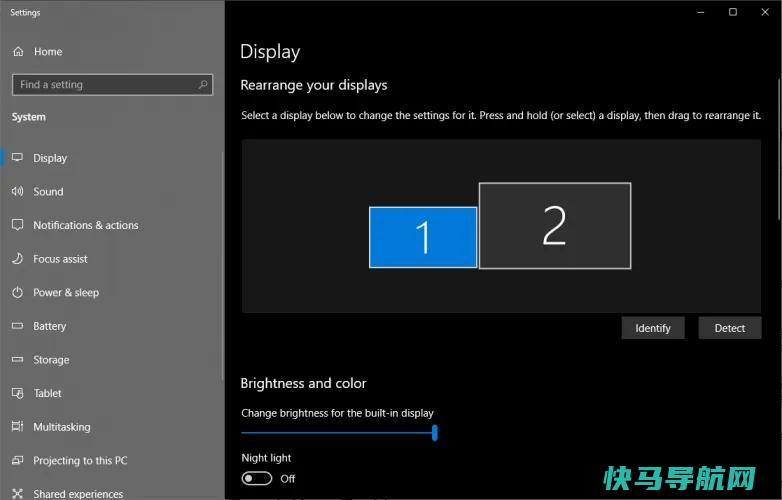
无论你是在努力工作还是在努力玩,多个智能显示器都会给你更多的空间来完成事情。在一个屏幕上编写文档,同时在另一个屏幕上引用网页。一个屏幕上玩游戏,另一个屏幕上不和谐地聊天。假装你在一个屏幕上专注于你的Zoom通话,而实际上你只是在另一个屏幕上聊天。如今,设置双显示器很容易,但不要只插入第二个显示器就结束了。一旦一切都设置好了,您可以做更...

猫云国内CDN,每月免费30G流量,支持HTTP2.09条评论深圳市猫云科技有限公司,以下简称猫云,刚成立不久,听过的朋友应该不多,目前主要提供CDN、云存储等业务,加入猫云联盟可获得每月30GCDN流量以及20G的云存储额度。关于猫云CDN猫云CDN融合了阿里云CDN、腾讯云CDN、网宿CDN、白山云CDN,而非自建CDN服务,稳定...
![[AD]必盛云推出Sectigo(原Comodo)免费SSL证书](https://www.q16k.com/zdmsl_image/article/20240329001147_22673.jpg)
[AD]必盛云推出Sectigo(原Comodo)免费SSL证书6条评论必盛云(Bisend)成立于2016年11月,隶属于上海小赤信息科技有限公司,主要经营云主机业务和SSL证书业务,在之前的文章《ComodoPositiveSSL证书两年只要98元》做过介绍,这次他们还推出了免费的SSL证书。前言网络安全越发重视的今天,越来越多的...

PDF是一种打开率很高的电子文件格式,特别是在工作中,很多文件都会生成PDF格式,方便阅读。虽然说现在支持浏览器打开,但无法编辑且容易误关闭,所以还是用软件更方便,那么PDF格式用什么打开?PDF的文件怎么打开?一、PDF是什么格式的文件Adobe公司的PDF是PortableDocumentFormat(便携文件格式)的缩写,是全世...