谷歌 TPU 超级算力大模型已超英伟达
尽管目前尚无与 ChatGPT 匹敌的AI大型模型,但在计算能力方面,领导者可能并非微软和 OpenAI。目前,谷歌发布了其基于 TPU 的超级计算机在训练大型语言模型方面的详细信息,该超级计算机在速度和能效方面已经超过了英伟达的同类产品。
 谷歌张量处理器(Tensor Processing Unit,TPU)是该公司为机器学习定制的专用集成电路(Application-Specific Integrated Circuit,ASIC)。自2016年发布第一代以来,TPU 便成为了 AlphaGo 背后的算力。与 GPU 相比,TPU 采用低精度计算,在几乎不影响深度学习处理效果的前提下显著降低了功耗并加快了运算速度。此外,TPU采用了脉动阵列等设计来优化矩阵乘法和卷积运算。目前,谷歌90%以上的人工智能训练任务都在使用这些芯片,而TPU支持了包括搜索在内的谷歌的主要业务。图灵奖获得者、计算机架构领域的杰出人物大卫・帕特森(David Patterson)在2016年从 UC Berkeley 退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了突出贡献。
谷歌张量处理器(Tensor Processing Unit,TPU)是该公司为机器学习定制的专用集成电路(Application-Specific Integrated Circuit,ASIC)。自2016年发布第一代以来,TPU 便成为了 AlphaGo 背后的算力。与 GPU 相比,TPU 采用低精度计算,在几乎不影响深度学习处理效果的前提下显著降低了功耗并加快了运算速度。此外,TPU采用了脉动阵列等设计来优化矩阵乘法和卷积运算。目前,谷歌90%以上的人工智能训练任务都在使用这些芯片,而TPU支持了包括搜索在内的谷歌的主要业务。图灵奖获得者、计算机架构领域的杰出人物大卫・帕特森(David Patterson)在2016年从 UC Berkeley 退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了突出贡献。
 如今,TPU 已发展至第四代。4月11日,由 Norman Jouppi、大卫・帕特森等人发表的论文《TPU v4: An Optically Reconfigurable Supercomputer For Machine Learning with Hardware Support for Embeddings》详细阐述了谷歌如何利用自研光通信器件将 4000 多个芯片并联组成超级计算机,从而提升整体效能。相较于 TPU v3,TPU v4 性能提升了2.1倍,功耗性能比增加了2.7倍。基于 TPU v4 的超级计算机拥有 4096 个芯片,整体速度提升约10倍。与类似规模的系统相比,谷歌的 TPU v4 比 Graphcore IPU Bow 快4.3-4.5倍,比 Nvidia A100 快1.2-1.7倍,功耗降低1.3-1.9倍。除了芯片本身的计算能力外,芯片间互连已成为构建AI超级计算机的企业间竞争的关键因素。近期,大型语言模型(LLM)如谷歌的 Bard 和 OpenAI 的的规模正呈爆炸式增长,计算能力已经成为显著的瓶颈。由于大型模型通常具有千亿级的参数量,数千个芯片必须共同分担训练任务,且训练过程可能持续数周甚至更长时间。谷歌的PaLM模型——迄今为止该公司披露的最大规模语言模型——在训练过程中被分配到两台拥有4000个TPU芯片的超级计算机上,耗时50天。谷歌表示,通过光电路交换机(Optical Circuit Switch, OCS),其超级计算机可以轻松地动态重新配置芯片间的连接,有助于避免问题并实时调整以提高性能。下图展示了 TPU v4 4×3 配置中的6个“面”的连接方式。每个面包含16条链路,每个模块总共有96条光链路连接到 OCS。为了提供3D环面的环绕连接,相对侧的连接必须接入相同的 OCS。因此,每个4×3模块的TPU连接到6×16÷2=48个 OCS。Palomar OCS 具有136×136规格(128个端口加上8个用于链路测试和修复的备用端口),因此来自64个4×3模块(每个包含64个芯片)的48对电缆共连接了48个 OCS,总计并联4096个 TPU v4 芯片。
如今,TPU 已发展至第四代。4月11日,由 Norman Jouppi、大卫・帕特森等人发表的论文《TPU v4: An Optically Reconfigurable Supercomputer For Machine Learning with Hardware Support for Embeddings》详细阐述了谷歌如何利用自研光通信器件将 4000 多个芯片并联组成超级计算机,从而提升整体效能。相较于 TPU v3,TPU v4 性能提升了2.1倍,功耗性能比增加了2.7倍。基于 TPU v4 的超级计算机拥有 4096 个芯片,整体速度提升约10倍。与类似规模的系统相比,谷歌的 TPU v4 比 Graphcore IPU Bow 快4.3-4.5倍,比 Nvidia A100 快1.2-1.7倍,功耗降低1.3-1.9倍。除了芯片本身的计算能力外,芯片间互连已成为构建AI超级计算机的企业间竞争的关键因素。近期,大型语言模型(LLM)如谷歌的 Bard 和 OpenAI 的的规模正呈爆炸式增长,计算能力已经成为显著的瓶颈。由于大型模型通常具有千亿级的参数量,数千个芯片必须共同分担训练任务,且训练过程可能持续数周甚至更长时间。谷歌的PaLM模型——迄今为止该公司披露的最大规模语言模型——在训练过程中被分配到两台拥有4000个TPU芯片的超级计算机上,耗时50天。谷歌表示,通过光电路交换机(Optical Circuit Switch, OCS),其超级计算机可以轻松地动态重新配置芯片间的连接,有助于避免问题并实时调整以提高性能。下图展示了 TPU v4 4×3 配置中的6个“面”的连接方式。每个面包含16条链路,每个模块总共有96条光链路连接到 OCS。为了提供3D环面的环绕连接,相对侧的连接必须接入相同的 OCS。因此,每个4×3模块的TPU连接到6×16÷2=48个 OCS。Palomar OCS 具有136×136规格(128个端口加上8个用于链路测试和修复的备用端口),因此来自64个4×3模块(每个包含64个芯片)的48对电缆共连接了48个 OCS,总计并联4096个 TPU v4 芯片。
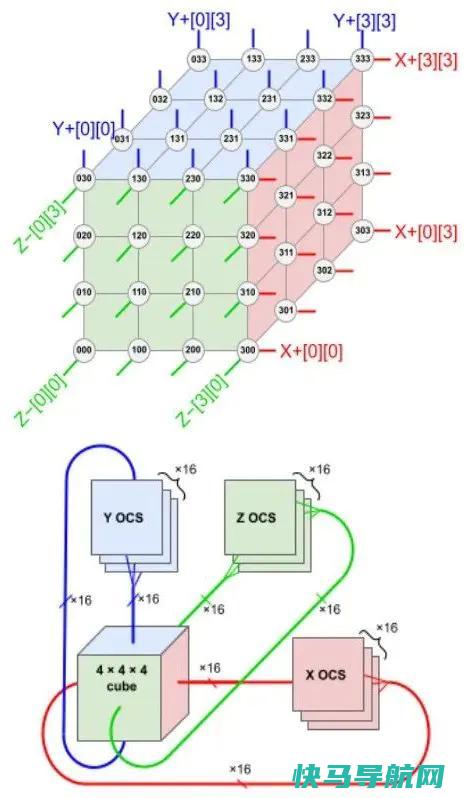 根据这样的排布,TPU v4(中间的 ASIC 加上 4 个 HBM 堆栈)和带有 4 个液冷封装的印刷电路板 (PCB)。该板的前面板有 4 个顶部 PCIe 连接器和 16 个底部 OSFP 连接器,用于托盘间 ICI 链接。随后,八个 64 芯片机架构成一台 4096 芯片超算。
根据这样的排布,TPU v4(中间的 ASIC 加上 4 个 HBM 堆栈)和带有 4 个液冷封装的印刷电路板 (PCB)。该板的前面板有 4 个顶部 PCIe 连接器和 16 个底部 OSFP 连接器,用于托盘间 ICI 链接。随后,八个 64 芯片机架构成一台 4096 芯片超算。
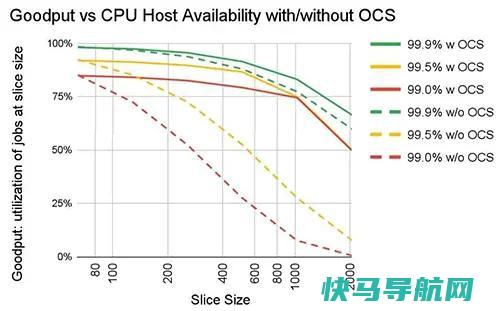
 在超级计算机中,工作负载由不同规模的算力承担,称为切片,如64芯片、128芯片、256芯片等。下图展示了在主机可用性从99.0%到99.9%不等,以及在没有 OCS 时,不同切片大小的“有效输出”。若无 OCS,主机可用性必须达到99.9%才能提供合理的切片吞吐量。对于大多数切片大小,OCS 在99.0%和99.5%的可用性下也表现出良好的输出。
在超级计算机中,工作负载由不同规模的算力承担,称为切片,如64芯片、128芯片、256芯片等。下图展示了在主机可用性从99.0%到99.9%不等,以及在没有 OCS 时,不同切片大小的“有效输出”。若无 OCS,主机可用性必须达到99.9%才能提供合理的切片吞吐量。对于大多数切片大小,OCS 在99.0%和99.5%的可用性下也表现出良好的输出。
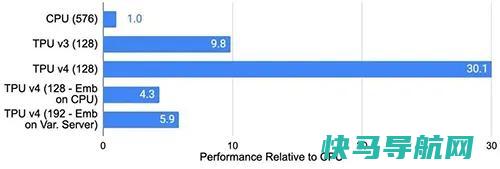
 与Infiniband相比,OCS 具有更低的成本、更低的功耗和更快的速度,占据系统成本不到5%,系统功率不到3%。每个 TPU v4 都包含 SparseCores 数据流处理器,能将依赖嵌入的模型加速5至7倍,但仅占用5%的裸片面积和功耗。谷歌研究员 Norm Jouppi 和谷歌杰出工程师大卫・帕特森在一篇关于该系统的博客文章中写道:这种切换机制使得绕过故障组件变得容易,其灵活性甚至允许我们改变超级计算机互连的拓扑结构,以加速机器学习模型的性能。TPU v4 比当代 DSA 芯片速度更快、功耗更低,如果考虑到互连技术,功率边缘可能会更大。通过使用具有 3D 环面拓扑的 3K TPU v4 切片,与 TPU v3 相比,谷歌的超算也能让 LLM 的训练时间大大减少。下图展示了谷歌自用的推荐模型(DLRM0)在不同芯片上的效率。TPU v3 比 CPU 快 9.8 倍。TPU v4 比 TPU v3 高 3.1 倍,比 CPU 高 30.1 倍。
与Infiniband相比,OCS 具有更低的成本、更低的功耗和更快的速度,占据系统成本不到5%,系统功率不到3%。每个 TPU v4 都包含 SparseCores 数据流处理器,能将依赖嵌入的模型加速5至7倍,但仅占用5%的裸片面积和功耗。谷歌研究员 Norm Jouppi 和谷歌杰出工程师大卫・帕特森在一篇关于该系统的博客文章中写道:这种切换机制使得绕过故障组件变得容易,其灵活性甚至允许我们改变超级计算机互连的拓扑结构,以加速机器学习模型的性能。TPU v4 比当代 DSA 芯片速度更快、功耗更低,如果考虑到互连技术,功率边缘可能会更大。通过使用具有 3D 环面拓扑的 3K TPU v4 切片,与 TPU v3 相比,谷歌的超算也能让 LLM 的训练时间大大减少。下图展示了谷歌自用的推荐模型(DLRM0)在不同芯片上的效率。TPU v3 比 CPU 快 9.8 倍。TPU v4 比 TPU v3 高 3.1 倍,比 CPU 高 30.1 倍。
 性能、可扩展性和可用性使 TPU v4 超级计算机成为 LaMDA、MUM 和 PaLM 等大型语言模型 (LLM) 的主要算力。这些功能使 5400 亿参数的 PaLM 模型在 TPU v4 超算上进行训练时,能够在 50 天内维持 57.8% 的峰值硬件浮点性能。谷歌表示,其已经部署了数十台 TPU v4 超级计算机,供内部使用和外部通过谷歌云使用。
性能、可扩展性和可用性使 TPU v4 超级计算机成为 LaMDA、MUM 和 PaLM 等大型语言模型 (LLM) 的主要算力。这些功能使 5400 亿参数的 PaLM 模型在 TPU v4 超算上进行训练时,能够在 50 天内维持 57.8% 的峰值硬件浮点性能。谷歌表示,其已经部署了数十台 TPU v4 超级计算机,供内部使用和外部通过谷歌云使用。
本文地址: https://www.q16k.com/article/b0727caac436330a243b.html

该站点未添加描述description...

该站点未添加描述description...

极击网是国内首家游戏玩家社交网站,轻松游戏,以玩交友

凤凰网汽车以服务全球华人汽车用户为己任,提供最新买车汽车报价、汽车图片、现车购买及互动论坛,第一时间发布汽车新车、试驾、评测、用车等丰富内容,是面向人群最广泛的专业门户汽车网站!

爱宝宝育儿网给大家分享怀孕期间孕期知识,分娩知识,婴幼儿健康,育儿经验心得大全

该站点未添加描述description...

爱码网是一个全网技术分享站,零门槛技术分享。在这里不需要积分,不需要注册,不需要充值,纯粹的技术分享。

该站点未添加描述description...

这是一款基于手机邮箱的qq邮件群发工具,可以使用99%以上的发件箱,群发国内国外邮箱,不进垃圾箱,稳定高效。

该站点未添加描述description...

22下载站分享手游通关攻略、app使用教程,并且提供海量的优质手机app/手机游戏供网友免费下载,本站的软件库和资讯攻略更新及时,内容丰富,是你玩转手机的好帮手!

17音乐专注于高品质乐器曲谱的发布于分享,提供:吉他谱、钢琴谱、尤克里里谱、小提琴谱、简谱等曲谱的下载服务。


该站点未添加描述description...

何氏宗亲网建站于2014年,是民间公益网站,是何氏文化传播与交流的综合性网站。其主旨是弘扬中华何氏文化,为全球何氏宗亲建立一个精神家园。

网易云音乐视频在线解析下载工具支持解析任何网易云音乐视频,包括MV、音乐短视频、好友动态视频等,并支持下载视频和视频封面到本地,手机和电脑上都适用.可谓是最简单的网易云音乐MV(视频)下载方法.


『3dmax低模』专注3d低模下载与3d模板模型制作和拓扑低模Lowpoly下载『ae模板』打造最新ae教程与最新ae特效相结合的ae素材cg插件下载『cg动画』更有cg动画的下载与制作教程


脑洞大大大攻略s型沙发的使用方法s型沙发的使用方法,s形沙发个人感觉是比较不错的,s形沙发坐着很舒服,他们的设计师非常注重人体力学,为研究让沙发曲线巧妙支撑人体的问题,下面是s型沙发的使用方法。s型沙发的使用方法1s形沙发可以随意组合摆放位置,弹簧能够从沙发的后部拖出来,与座面软垫分开,并在它的上面铺上软垫,构成一张双人床。不仅适合用来坐,同样也可...

劫尽1 0a攻略生活中我们都知道喝纯牛奶对身体有益。主要是因为纯牛奶进入人体后,会优先消耗乳糖与脂肪转化为热量,之后才消耗蛋白质,为人体提供营养,而不是简单的“穿肠过”。牛奶中含有微量元素锌与钙等物质,饮用能为人体补充丰富的矿物质,下面为您详细的一一介绍,希望有用。本文目录1、经常喝纯牛奶的好处与坏处2、纯牛奶可以做什么简单的美食3、能不能空腹喝纯牛...

100个门2013图文攻略绿豆又叫青小豆,是我国人民的传统豆类食物。绿豆中的多种维生素、钙、磷、铁等无机盐都比粳米多。因此,它不但具有良好的价值,还具有非常好的药用价值。有“济世之良谷”的说法。在炎炎夏日,绿豆汤更是老百姓最喜欢的消暑清热解毒饮料,注意的是,如果在吃药期间,就不要喝绿豆汤了,医生说会降低药效。下面,和360健康网一起看看绿豆汤为什么会变红?变红...

华夏的美食成千上万种,即连一路满汉全席,皆是上百道菜,会集了各个地点的美食,普遍皆是各个省分最有名望,且仍旧有了上百年史籍的食品,要道小七追念中回顾最深的那即数北京烤鸭、烤乳猪等,这些算是名望比拟大的方圆美食了,讲到烤乳猪,小七每每看到美食博主们,直播吃一头烤乳猪,本来烤乳猪的价钱也没有廉价呢,一只即是上百元,惟有土豪技能吃得起。咱们...

小暑从速要到了,气象也愈来愈热,好多人皆没有胃口。尔身旁有一部分女生想要减肥瘦身,晚饭没有用饭大概只用生果来替代,这类做法小编本来是特地没有倡导的,由于有些生果中的糖分本来没有矮,而且只吃一种食品或者是没有用饭,到夜半简易感应饥饿,没有利于形体安康。以是,仍旧倡导全体适当食用晚饭,吃七八分鼓便够了,吃一点安康且有养分的蔬菜,有利于体魄...
糙米酒糟吃米酒的一种是以糙米为主要原料,经发酵酿之后得到的健康酒水,人们也用它以后能活血消肿并能补益气血,缓解体虚,对维持人体健康有极大好处,下面是对糙米酒糟功效的具体介绍,能让大家对它有更详细的了解。糙米酒糟有什么功效1、丰胸糙米酒糟是最适合女性食用的健康饮品,它具有很明显的丰胸作用,因为糙米酒糟中含有能促进女性胸部发育的天然荷尔蒙...

在沙棘果成熟的时候,人们喜欢在野外采集新鲜沙棘果后回家洗净直接吃,其实吃不完的沙棘果还可以晒干以后保存起来,而晒干后的沙棘果就可以用来泡水喝,人们用沙棘果泡水也能吸收沙棘果中的丰富营养,而且能保健身体预防疾病,想知道沙棘果泡水喝的具体功效,可以和小编一起去看看。沙棘果泡水喝的功效与作用1、提高心脏功能人们在日常生活中用沙棘果泡水喝,能...

在这一点上,罗技在其消费者和游戏部门提供了不少于15个机械键盘。因此,当我说PopKey是独一无二的时,这实际上意味着一些东西。在这样一个主流品牌中,你找不到其他任何与它非常相似的产品。机械实用性和有趣风格的结合应该有广泛的吸引力,或者至少比通常的灰色和黑色矩形更具视觉趣味性。这就是PopKey的最大优势–我们在这里看到的是风格重于实...

事实证明,谷歌对可以上传到其云存储服务GoogleDrive的文件数量施加了硬性限制–尽管缺乏概述这些限制的明确文件。那个神奇的数字?五百万。只有当用户开始使用它时,这种隐藏的计数才会变得明显。根据Reddit上的报道和CNET的分享,用户在2月份艰难地发现了这个帽子。在谷歌IssueTracker上的一篇帖子中,个人和企业都指出,上...
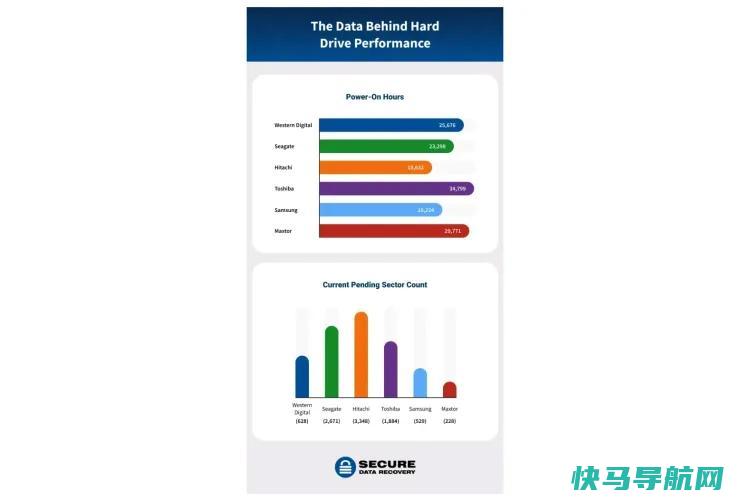
最近一份关于硬盘驱动器可靠性的报告表明,不仅大多数硬盘驱动器会在三年内报废,2014年后生产的硬盘驱动器也可能不那么可靠。对于许多人来说,这样的消息可能标志着HDD加速消亡的充分理由-至少对于消费者来说是这样。随着固态硬盘价格的下降和可用容量的逐渐增加,固态硬盘在笔记本电脑中几乎无处不在,在台式PC中占据主导地位。事实上,我自己经常向...

Windows任务栏中的时钟可以显示秒吗?从历史上看没有,但这在微软内部已经争论了很多年–最近Windows11的更新已经平息了这一争论。现在,你可以选择在任务栏的时钟上显示秒。通过这一改变,Windows11打破了Windows的旧传统。但首先要做的是。Windows11的S任务栏时钟现在显示秒数在对Windows11的Inside...

微软正在开发一种方便的方式来共享Windows11的Wi-Fi接入,Windows最新发现了这一点。Windows11的S最新的InsiderDevChannel预览版本可以在您的台式PC或Windows笔记本电脑的屏幕上显示二维码,然后智能手机或平板电脑用户只需用他们的相机扫描,然后连接到与WindowsPC相同的Wi-Fi网络。整...

尽管近两年来蒸汽甲板一直是PC游戏的热门门票,但不可否认的是,它在一些硬件方面有点落后于时代。例如,7英寸的触摸屏还有很多不足之处–自那以来,它一直被联想和华硕等公司的竞争所击败。这是蒸汽甲板推出以来的第一次重大翻新,现在你可以订购一台配备令人眼花缭乱的7.4英寸OLED屏幕的平板电脑。更新的机型还配备了更大的电池和更多的存储空间。蒸...

本文目录导航:网络营销是什么专业网络营销这个专业的就业方向是哪些方面?网络营销专业就业方向有哪些网络营销是什么专业网络营销是高校管理学专业,主要培养具有独创精神和较强实践能力,能熟练运用计算机网络进行市场营销和销售管理,包括网络营销基本策略的制定和实施、营销型网站建设、搜索引擎营销、网络广告、网店运营、客户服务等,懂技术、懂营销、懂网...

开通百度logo权限可能是白天做网站最执着的事情之一了,不论方法可不可行,都有做尝试,无奈都没有结果,所以最终还是只好老老实实的按照百度搜索规范提升网站质量等待系统自动开通,但等待这条“路”的过程可能会漫长到遥遥无期。至于为什么会发这篇文章,那是因为,就在今天白天总算是通过自己的努力获得了开通百度logo权限的机会,所以打算分享给大家...

目前,主流跨境电商平台以速卖通和亚马逊平台为主。而Lazada和Shopee,是瞄准6亿人口东南亚市场的两大主流电商平台,也是马来西亚最大的电商平台之一,两者都拥有巨大的流量以及可观的平台销量。本文快马导航网SEO给大家分享Lazada和Shopee区别是什么?哪个平台比较好?一、平台流量表现两个平台流量平分秋色,市场和用户高度重叠,...

咱们的团体消息安保也遭到了重大的要挟,随着社交媒体平台的遍及。不少用户担忧自己的位置消息被暴露,而抖音作为以后的短视频平台之一,成为了宽广用户最关心的话题之一。而抖音IP地址显示能否实在,就是其中之一。一、什么是IP地址?IP地址是一个设施在互联网中的身份证实,每个设施都有一个IP地址用于标识其在网络中的位置。繁难来说,IP地址就是一...

视频显示大阪上空有10个发白光的球形不明航行物这些不明航行物在地面漂浮日本大阪上空出现10个不明航行物据国内在线:英国《镜报》7月27日报道,最近一段视频在网络上惹起了人们的留意,这段视频显示,10个红色的球形物在日本大阪上空飘浮。视频长约2分钟,10个不明物体发着不同寻常的白光,并且极速地移动、飘摇。人们可以明晰地看到这些不明航行物...

淘宝抢红包攻略已婚女性与异性朋友交往的原则已婚女性与异性朋友交往的原则,虽然有某些男人会限制自己的老婆在婚后有异性朋友,但是大多数男人还是不介意自己的老婆有异性朋友的,不过就算是男人不介意婚后女人也要把握好和异性朋友相处的分寸,那么已婚女性与异性朋友交往的原则是什么呢。已婚女性与异性朋友交往的原则11、明确自己的身份,自律自爱且有且珍惜,即使面前有...

上古神器3攻略尿频尿痛常规诊断:尿路感染。可能疾病:间质性膀胱炎。圣约瑟夫医院泌尿科专家布莱恩·诺罗兹博士:如使用抗生素一疗程后,尿路感染典型症状仍不消退,应怀疑间质性膀胱炎的可能,其另外一个特征是不会引起发烧。间质性膀胱炎的表现常常与尿路感染相似。在病程的早期,一般都有感染的因素存在,易被误诊。情绪多变体重增加常规诊断:抑郁症。可能疾病:甲状腺功...

战争之王攻略真露酒属于什么酒?真露酒是韩国烧酒,真露酒是韩国最大的烧酒品牌,被称为韩国“白酒”,真露酒的历史非常悠久,距今为止已经将近有百年的历史,珍露酒起源于中国元朝的烧酎,曾经一度在韩国被列为高级酒,民间禁止制造,在二十世纪初才走向平民化。真露酒属于烧酒1、真露酒是韩国烧酒真露是韩国最大的烧酒品牌,真露也算是韩国代表性的烧酒,在韩国的地位相当...
婴儿逃出系列3攻略世界上有很多种动物,什么动物最吓人,关于这个问题大家各有各的看法,今天我来跟大家介绍一下,我认为的世界上最吓人的动物,是黑寡妇蜘蛛、眼镜蛇、蜱虫,前两个动物身体都含有剧毒,死在这两种动物的人不在少数,而蜱虫也算是最吓人的动物,蜱虫属于寄生虫,身体携带多种疾病,给人带来不小的威胁。最吓人的动物1、蜱虫蜱虫属于寄生虫,很多动物不注意卫生的...

仙5全攻略普拉提将瑜伽、太极拳、芭蕾形式的教练个性化内容结合起来。易于学习,不仅动作平缓,而且有针对性地用于手臂、胸部和肩部锻炼,同时增强身体的灵活性。这项运动不受活动地点的限制,下面,就快和360常识网一起了解相关知识吧!本文目录1、普拉提练多久看出变化?2、哪些人适合做普拉提3、普拉提的练习动作有什么普拉提练多久看出变化?当普拉提与一般的运...