robots文件介绍、作用及写法
在接手一个网站时,无论做什么诊断分析,都少不了检查 robots文件 ,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。

一、robots文件简介
简单来说就是一个以robots命名的txt格式的文本文件,是网站跟爬虫间的协议(你可以理解为搜索引擎蜘蛛抓取的规则),当搜索引擎发现一个新的站点时,首先会检查该站点是否存在robots文件,如果存在,搜索引擎则会跟据robots文件规定的规则来确定可以访问该站点的范围。
二、robots文件的作用
1.禁止搜索引擎收录网站,以保障网站的安全。比如一些网站是客户管理系统,只需要公司员工登录即可,属于并不想公开的私密信息,为了防止信息泄露就可以使用robots文件进行屏蔽抓取。
2.网站内的部分目录或内容如果不希望搜索引擎抓取,如WordPress的后台文件 wp-admin,管理仪表盘或其他页面,这些对搜索引擎无用的页面就可以借助robots文件来告诉搜索引擎不要抓取此目录下的内容,这样就可以让有限带宽的蜘蛛深入抓取更多需要被抓取收录的页面。
3.屏蔽一些动态链接,统一网站链接类型,集中权重。
三、robots文件写法
1、首先先来了解下robots文件里的内容由那几部分构成:
一个robots文件,不同的写法有不同的意义,常见的robots文件由User-agent、Allow、Disallow 等组成。另外,我们也经常会在robots文件中添加网站 sitemap 文件的链接以引导搜索引擎爬虫抓取。举一个例子:
User-agent: Baiduspider Allow: /wp-content/uploads/ Disallow: /w? Sitemap: https:/www.seobti.com/sitemap.xml
该例子中就包含有User-agent、Allow、Disallow 、Sitemap等。下面具体来解释下各自的作用。
User-agent: 该项的值用于描述搜索引擎robot的名字。在robots.txt文件中,至少要有一条User-agent记录。如果该项的值设为*(即:“User-agent:*”),则对任何robot均有效。另外如果只针对百度搜索引擎,则该项的值为:Baiduspider(即:“User-agent:Baiduspider”)。
该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。
举例说明:
该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的。
举例说明:
以上是sitemap组成常见的部分,为了让robots写法更准确,我们还可以使用借助“”and “”来更精确的制定搜索引擎抓取规则。
:robots文件中可以使用通配符“*”和“$”来模糊匹配url。“*” 匹配0或多个任意字符, “$” 匹配行结束符。
举例说明:
2、格式
在robots文件中,一个“
User-agent
”代表一条记录,且这样的记录可以包含一条或多条记录。如:
一条记录
User-agent: * Disallow: /template/ #该协议只有一条记录,该协议对所有搜索引擎有效
多条记录
User-agent: Baiduspider Disallow: /w? Disallow: /client/User-agent: Googlebot Disallow: /update Disallow: /historyUser-agent: bingbot Disallow: /usercard#多条记录,针对不同的搜索引擎使用不同的协议
注意
:“
User-agent: *
”中的“*”是通配符的意思, 也就是说该记录下的协议适用任何搜索引擎,而“
User-agent: Baiduspider
”中的“Baiduspider”是百度搜索引擎的爬取程序名称,也就是该协议只针对百度搜索引擎。
一般来说,优化的对象如果只针对国内的用户,那么就可以使用多条记录的方式来限制国外搜索引擎的抓取,以此可以节省服务器部分资源,减小服务器压力。
另外需要注意的是: robots.txt文件中只能有一条 “User-agent: *”这样的记录。
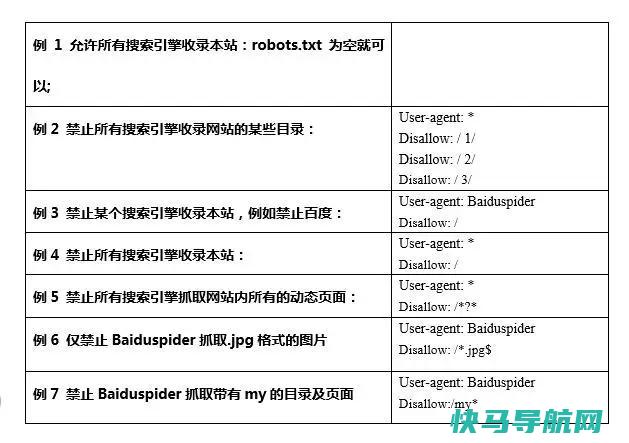
3、语法说明
这里主要列举几种比较常见的写法,如图2所示:
4、注释
为了方便理解,我们可以在robots文件里添加注释,在每一行以“ # ”开头即可(类似于服务器配置文件中的写法规则)。如图3所示:

四、使用robots文件需要注意的一些事项
1、robots文件应放在网站根目录,链接地址为:www.xxx.com/robots.txt;
2、鉴于不希望搜索引擎收录网站的隐私文件,可以使用robots文件来禁止抓取,但这样却正好可以被黑客所利用, 所以robots文件并不能保证网站的隐私,因此在robots规则时,可以使用“*”来模糊匹配。 如:Disallow:/my*;
3、“
Disallow: /help
”与“
Disallow: /help/
”规定的抓取范围有所不同,“/help”包含“/help.html、/help*.html、/help/index.html”等页面,而“/help/”不包含“/help.html、/help*.html”等页面。
五、robots的其他用法
除了使用 robots.txt 来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取外,robots还有另外一些写法—— Robots meta 标签。
Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而Robots Meta标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots Meta标签也是放在页面中,专门用来告诉搜索引擎爬虫如何抓取该页的内容。
Robots Meta标签中没有大小写之分,
name="robots"
表示所有的搜索引擎,可以针对某个具体搜索引擎写为
name="BaiduSpider"
。
content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。
具体写法有以下四种:
其中:
可以写成
而
可以写成
另外著名搜索引擎 Google 还增加了一个指令“archive”,可以限制Google是否保留网页快照。例如:
需要注意的是并不是所有的搜索引擎都支持Robots meta标签写法。
过去的今天:
robots文件 SEO术语原创文章,作者:白天,如若转载请注明出处: robots文件介绍、作用及写法
求SEO高手指点robots文件的相关语法!
robots基本概念文件是网站的一个文件,它是给搜索引擎蜘蛛看的。 搜索引擎蜘蛛爬行道我们的网站首先就是抓取这个文件,根据里面的内容来决定对网站文件访问的范围。 它能够保护我们的一些文件不暴露在搜索引擎之下,从而有效的控制蜘蛛的爬取路径,为我们站长做好seo创造必要的条件。 尤其是我们的网站刚刚创建,有些内容还不完善,暂时还不想被搜索引擎收录时。 也可用在某一目录中。 对这一目录下的文件进行搜索范围设定。 几点注意:网站必须要有一个文件。 文件名是小写字母。 当需要完全屏蔽文件时,需要配合meta的robots属性。 的基本语法内容项的基本格式:键: 值对。 1) User-Agent键后面的内容对应的是各个具体的搜索引擎爬行器的名称。 如网络是Baiduspider,谷歌是Googlebot。 一般我们这样写:User-Agent: *表示允许所有搜索引擎蜘蛛来爬行抓取。 如果只想让某一个搜索引擎蜘蛛来爬行,在后面列出名字即可。 如果是多个,则重复写。 注意:User-Agent:后面要有一个空格。 在中,键后面加:号,后面必有一个空格,和值相区分开。 2)Disallow键该键用来说明不允许搜索引擎蜘蛛抓取的URL路径。 例如:Disallow: / 禁止网站文件Allow键该键说明允许搜索引擎蜘蛛爬行的URL路径例如:Allow: / 允许网站的通配符*代表任意多个字符例如:Disallow: /* 网站所有的jpg文件被禁止了。 结束符$表示以前面字符结束的url。 例如:Disallow: /?$ 网站所有以?结尾的文件被禁止。 四、实例分析例1. 禁止所有搜索引擎访问网站的任何部分User-agent: *Disallow: /例2. 允许所有的搜索引擎访问网站的任何部分User-agent: *Disallow:例3. 仅禁止Baiduspider访问您的网站User-agent: BaiduspiderDisallow: /例4. 仅允许Baiduspider访问您的网站User-agent: BaiduspiderDisallow:例5. 禁止spider访问特定目录User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /data/注意事项:1)三个目录要分别写。 2)请注意最后要带斜杠。 3)带斜杠与不带斜杠的区别。 例6. 允许访问特定目录中的部分url我希望a目录下只有允许访问,怎么写?User-agent: *Allow: /a/: /a/注:允许收录优先级要高于禁止收录。 从例7开始说明通配符的使用。 通配符包括($ 结束符;*任意符)例7. 禁止访问网站中所有的动态页面User-agent: *Disallow: /*?*例8. 禁止搜索引擎抓取网站上所有图片User-agent: *Disallow: /*$Disallow: /*$Disallow: /*$Disallow: /*$Disallow: /*$其他很多情况呢,需要具体情况具体分析。 只要你了解了这些语法规则以及通配符的使用,相信很多情况是可以解决的。 meta robots标签meta是网页html文件的head标签里面的标签内容。 它规定了此html文件对与搜索引擎的抓取规则。 与 不同,它只针对写在此html的文件。 写法: 。 …里面的内容列出如下noindex - 阻止页面被列入索引。 nofollow - 阻止对于页面中任何超级链接进行索引。 noarchive - 不保存该页面的网页快照。 nosnippet - 不在搜索结果中显示该页面的摘要信息,同时不保存该页面的网页快照。 noodp - 在搜索结果中不使用Open Directory Project中的描述信息作为其摘要信息。
robots文件是什么意思?他对网站的优化能起到什么作用?
是什么是搜索引擎中访问网站的时候要查看的第一个文件。 文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。 必须放置在一个站点的根目录下,而且文件名必须全部小写。 语法:最简单的 文件使用两条规则:User-Agent: 适用下列规则的漫游器 Disallow: 要拦截的网页下载该文件 有几个常用的写法;全部开放或全部禁止{User-agent: *//表示站内针地所有搜索引擎开放;Allow: ///允许索引所有的目录;User-agent: *//表示站内针地所有搜索引擎开放;Disallow: / //禁止索引所有的目录;User-agent: *//表示站内针地所有搜索引擎开放;Disallow: //允许索引所有的目录;}这里呢,可以把[网站地图(Sitemap)] 也加进来,引导搜索引擎抓取网站地图里的内容。 Sitemap: 使用方法:例1. 禁止所有搜索引擎访问网站的任何部分 Disallow: /例2. 允许所有的robot访问(或者也可以建一个空文件 /)User-agent: *Disallow: 或者User-agent: *Allow: / 例3. 仅禁止Baiduspider访问您的网站 User-agent: BaiduspiderDisallow: /例4. 仅允许Baiduspider访问您的网站 User-agent: BaiduspiderDisallow:User-agent: *Disallow: /例5. 禁止spider访问特定目录在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即robot不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不能写成 Disallow: /cgi-bin/ /tmp/。 User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/例6.要阻止 Googlebot 抓取特定文件类型(例如,)的所有文件User-agent: GooglebotDisallow: /*$例7.要阻止 Googlebot 抓取所有包含 ? 的网址(具体地说,这种网址以您的域名开头,后接任意字符串,然后是问号,而后又是任意字符串)User-agent: GooglebotDisallow: /*? 更多有才资料:
robots.txt文件要怎么写
大家先了解下文件是什么,有什么作用。 搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛”蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是。 这个文件其实就是给“蜘蛛”的规则,如果没有这个文件,蜘蛛会认为你的网站同意全部抓取网页。 文件是一个纯文本文件,可以告诉蜘蛛哪些页面可以爬取(收录),哪些页面不能爬取。 举个例子:建立一个名为的文本文件,然后输入User-agent: * 星号说明允许所有搜索引擎收录Disallow: ? 表示不允许收录以?前缀的链接,比如?=865Disallow: /tmp/ 表示不允许收录根目录下的tmp目录,包括目录下的文件,比如tmp/具体使用方法网络和谷歌都有解释,网络文件可以帮助我们让搜索引擎删除已收录的页面,大概需要30-50天。
本文地址: https://www.q16k.com/article/1176340c445a1f5a5ec4.html

濮阳电脑上门维修是专业的电脑维修店,为广大个人PC用户和企业用户提供专业、优质的家用电脑及企业电脑相关设备的维修维护,并为企业用户提供长期的计算机网络设备的组健及维护。我们将以迅捷的速度、最专业的技术、最规范的体系为您提供最满意的服务!电脑知识 电脑技术电脑技术交流0393-7777365
中国传媒大学继续教育学院主要提供函授、成人教育、网络教育、在职培训、传媒等网络教育的平台
武汉馨梦想时代广告有限公司为您提供优质的广告喷绘服务,是专业的武汉广告喷绘、大型喷绘广告工厂,武汉做大型广告就找馨梦想时代广告.
该站点未添加描述description...
欣欣吉林旅游网提供吉林旅行社发布的旅游线路、吉林旅游景点介绍、吉林旅游攻略、吉林订房、订票、导游和租车等出行指南及旅游服务●欣欣旅游网CNCN.com
连云港房产网为您提供全面、及时、专业的连云港房地产信息资讯,为连云港楼市构建系统、完善的房产交易电子商务平台,为连云港百姓生活打造自由、专属的业主社区。
该站点未添加描述description...
泊头市清清除尘有限公司为您提供专业的除尘设备及配件等服务,公司位于河北省,沧州市,泊头市,欢迎来电咨询:15933178962。
互联网订单农业,胚芽鲜米,绿色有机农产品
三千万用户正在使用的公考、教师、司法、考研、建造、会计考试的提分利器。高品质直播课+海量题库,公考、教师、司法、考研、建造和会计考试的好帮手。

该站点未添加描述description...
广州千课教育科技有限公司是国内领先的职业教育在线教育机构,旗下拥有鸭题库、雪狐狸等众多品牌,培训范围涵盖执业药师、护士资格、药师职称、消防工程师、经济师、执业医师、会计职称、教师职称、建造师、健康管理师、python编程、经济师等多个门类。公司助力百万学子职业发展,重新定义教育标准,给您极致的课程与服务。
普陀山旅游网,舟山旅游网,舟山南国旅行社有限公司
该站点未添加描述description...
网站首页,勃发创新设计领军者专业设计20年13840444658,致力于沈阳标志设计,包装设计,画册设计,VI设计,网站设计,店面设计装修等。电话13840444658。
零距离理财网是常熟地区专业的理财网站,提供常熟本地银行服务信息,理财产品、信用卡在线申请,保险、外汇、股票、期货资讯时时新鲜。常熟理财信息,尽在零距离理财网。
柴都导航汇集全网优质网址及资源。包含小说、音乐、影视、游戏、购物等分类的网址和内容,提供最简单便捷的网址导航服务,深受网民欢迎和喜爱。柴都导航,您值得拥有的上网主页!
南京防腐木|南京园林景观|柳桉防腐木|菠萝格|南京圣兰木业有限公司www.njslmy.com经营范围含:能源、木制工艺品、鹅苗、特种建材、量器量具、色谱仪、陶瓷工艺品、安防、毛巾、养殖动物(依法须经批准的项目,经相关部门批准后方可开展经营活动)。

在接手一个网站时,无论做什么诊断分析,都少不了检查robots文件,为什么有的网站天天发文章却未见收录,很有可能是因为被robots文件里的规则屏蔽搜索引擎抓取所导致的。那么什么是robots文件,对于一个网站它的作用的什么?本文白天为你详细介绍robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

有时候有些页面访问消耗性能比较高不想让搜索引擎抓取,可以在根目录下放robots.txt文件屏蔽搜索引擎或者设置搜索引擎可以抓取文件范围以及规则。Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面...

相信做过网站优化的朋友都听过robots文件和,但是大家真正清楚它们的作用与用途吗?不瞒大家说,白天也经常犯迷糊,好像他们的作用是一样的。但这真的只是好像,它们的不同点反而很多。那么本篇文章白天就来给大家讲讲经过多次研究后,说说白天对robots与nofollow的理解。首先先从它们的定义开始:robots在网站里通常是指robots...

在接手一个网站时,无论做什么诊断剖析,都少不了审核robots文件,为什么有的网站天天发文章却未见收录,很有或许是由于被robots文件里的规则屏蔽搜查引擎抓取所造成的。那么什么是robots文件,关于一个网站它的作用的什么?本文白昼为你详细引见robots文件并教你robots文件正确的写法。图1robots文件一、robots文件...

我们都知道网站想要有排名必须要先增加百度收录,同时标题要包含指数关键词,这样才可以提高第三方平台的百度权重值,我们在交换友链时收录数量也是一个交换的标准,比如你的网站收录是一万,我想你不会跟收录只有100的网站做链接。新网站想要增加百度收录除了内容要优质外,还要通过外部链接引蜘蛛到访,并且网站的robots文件没有拒绝蜘蛛爬行,日更文...
我之前较多时间专注在SEO渠道,有个职业规划方向就是做全渠道的运营,所以近几年有尝试参与其他流量渠道,比如联盟、网红、社交媒体等。另外也观察到一些项目存在流量渠道单一、新渠道未覆盖等问题。所以对跨境电商全渠道的顶层设计做了一些思考,也有幸跟Jessy做了一些请教,于是整理和分享出来。全渠道模型从渠道营销的思路,有2个核心逻辑:「哪里有...

今年6月,索尼推出了一款全新的分级PlayStationPlus,取代了现有的订阅服务。一个月后,这家游戏巨头宣布了PlayStationStars,这是一个奖励和忠诚度计划。很自然,您可能会对这两种服务之间的区别感到困惑。不要着急,我们在这里强调这对情侣的特点,这样你就可以在签约之前做出明智的决定。旧的PSPlus和PS现在发生了什...

KryptiON云上线,双向CN2网络,年付五折优惠4条评论1998年5月,Krypt在加州NewportBeach市成立了网站托管公司。Krypt公司最为著名的是在2000-2005年间CS游戏产业达到巅峰的时候,是美国西海岸最好的CS游戏服务器提供商。年付5折优惠Krypt为庆祝iON云上线,献上年付五折优惠码:,iON云使用的技...
AI生成的文章大都有一个特色,很多惯用词、废话、缺乏情感传达等等。总之,AI生成的文章是不能直接使用的。至少需要解决AI感重的问题。本文结合MattDiggity分享的一些ChatGPT提示词,帮你解决的就是文章产出后AI感太重的问题。为了测试实验效果,MattDiggity还召集了一批真人读者,来给他用这些提示词生成的文章打分。结果...

404页面是影响SEO优化的一个重要因素,同时也是SEO优化需要注意到的一个细节。刚开始学SEO的朋友可能不了解404页面,不清楚404页面有什么用以至于不会对404页面有太多关注…实际上,每个网站都会有404页面,只是展现的形式不一样,有的网站没有优化404页面,可能展现的就只是一个“404,页面找不到”的几个大字,如果用户访问到网...